change buffer 基础逻辑
首先,明确 mysql 有一个概念 change buffer。当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
如果能够将更新操作先记录在 change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用 buffer pool 的,所以这种方式还能够避免占用内存,提高内存利用率。
change buffer 存的是变动方式,而不是变动后的数据值。
change buffer & redo log 运作情况
> insert into t(id,k) values(id1,k1),(id2,k2)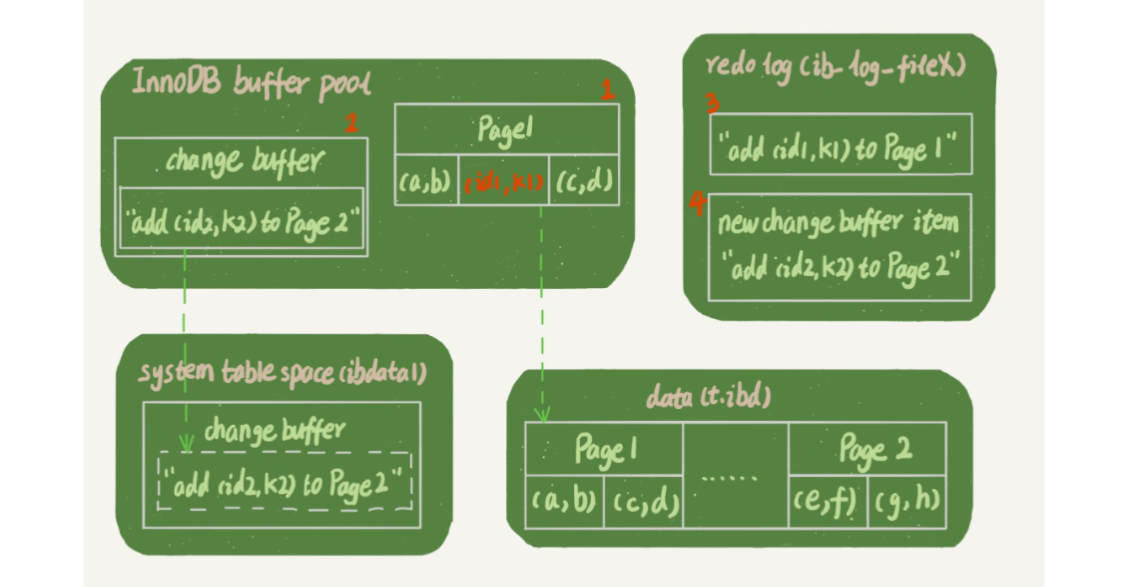
这条插入语句共设计四个部分:内存、redo log (ib_log_fileX)、数据表空间(t.ibd)、系统表空间(ibdata1)。
更新操作如下:
- Page 1 在内存中,直接更新内存。
- Page 2 没有在内存中,就在内存的 change buffer 区域,记录下“在 Page2 中插入一行”的信息。
- 将上述两个动作写入 redo log 中(图中 3 和 4)。
select * from t where k in (k1, k2);如果插入语句执行不久后,又进行查询语句,内存数据还在,那么此时两个读操作就与系统表空间和 redo log 无关了。
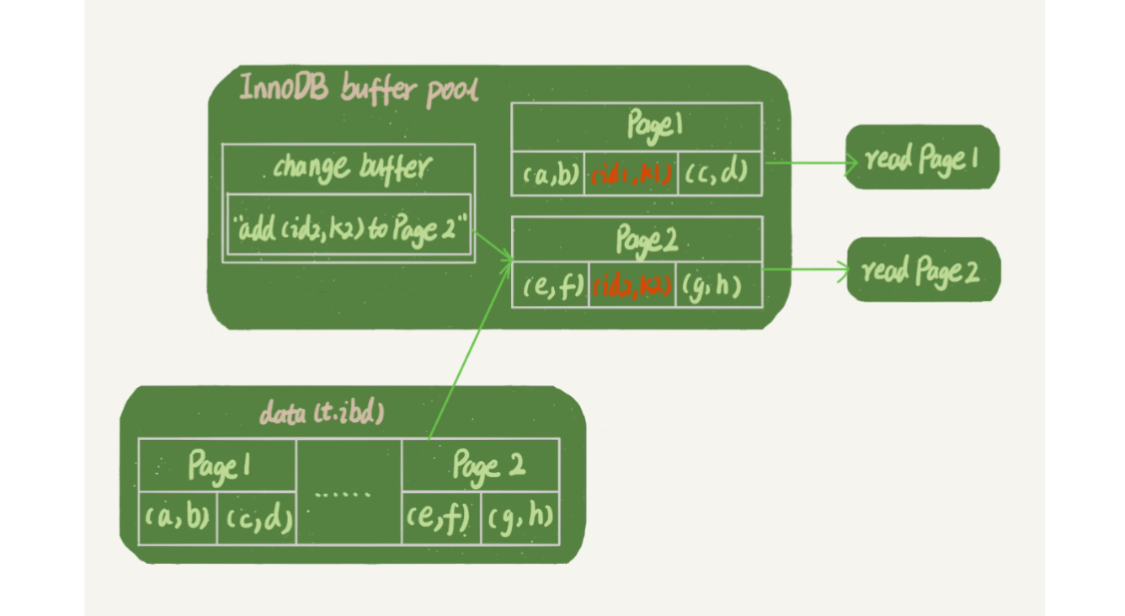
读操作如下:
- 读 Page1 时直接从内存返回。
- 读 Page2 时,需要将 Page2 从磁盘读入内存,然后应用 change buffer 的操作日志,生成一个正确版本并返回结果。
redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写)
而 change buffer 主要节省的则是随机读磁盘的 IO 消耗。
什么索引条件下可以使用 change buffer 呢?
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。比如,要插入(4,400)这个记录,就要先判断现在表中是否已经存在 k=4 的记录,而这必须要将数据页读入内存才能判断。如果都已经读入到内存了,那直接更新内存会更快,就没必要使用 change buffer 了。因此,唯一索引的更新就不能使用 change buffer,实际上也只有普通索引可以使用。
change buffer 的使用场景
通过上面的分析,你已经清楚了使用 change buffer 对更新过程的加速作用,也清楚了 change buffer 只限于用在普通索引的场景下,而不适用于唯一索引。那么,现在有一个问题就是:普通索引的所有场景,使用 change buffer 都可以起到加速作用吗?
因为 merge 的时候是真正进行数据更新的时刻,而 change buffer 的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做 merge 之前,change buffer 记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。
因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时 change buffer 的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。
反过来,假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在 change buffer,但之后由于马上要访问这个数据页,会立即触发 merge 过程。这样随机访问 IO 的次数不会减少,反而增加了 change buffer 的维护代价。所以,对于这种业务模式来说,change buffer 反而起到了副作用。如果所有的更新后面,都马上伴随着对这个记录的查询,那么你应该关闭 change buffer。而在其他情况下,change buffer 都能提升更新性能。
change buffer 存在内存中,若机器断电重启,会丢失数据吗?
事务提交的时候,会将 change buffer 写入到 redo log 中。所以,如果事务已经提交了,那么数据就不会丢失;事务还没有提交,那么数据就不应该被修改,不算丢失数据。