union 执行流程
为了便于量化分析,我用下面的表 t1 来举例。
create table t1(id int primary key, a int, b int, index(a));
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();然后,我们执行下面这条语句:
(select 1000 as f) union (select id from t1 order by id desc limit 2);这条语句用到了 union,它的语义是,取这两个子查询结果的并集。并集的意思就是这两个集合加起来,重复的行只保留一行。
下图是这个语句的 explain 结果。

可以看到:
- 第二行的 key=PRIMARY,说明第二个子句用到了索引 id。
- 第三行的 Extra 字段,表示在对子查询的结果集做 union 的时候,使用了临时表 (Using temporary)。
这个语句的执行流程是这样的:
- 创建一个内存临时表,这个临时表只有一个整型字段 f,并且 f 是主键字段。
- 执行第一个子查询,得到 1000 这个值,并存入临时表中。
- 执行第二个子查询:
- 拿到第一行 id=1000,试图插入临时表中。但由于 1000 这个值已经存在于临时表了,违反了唯一性约束,所以插入失败,然后继续执行;
- 取到第二行 id=999,插入临时表成功。
- 从临时表中按行取出数据,返回结果,并删除临时表,结果中包含两行数据分别是 1000 和 999。
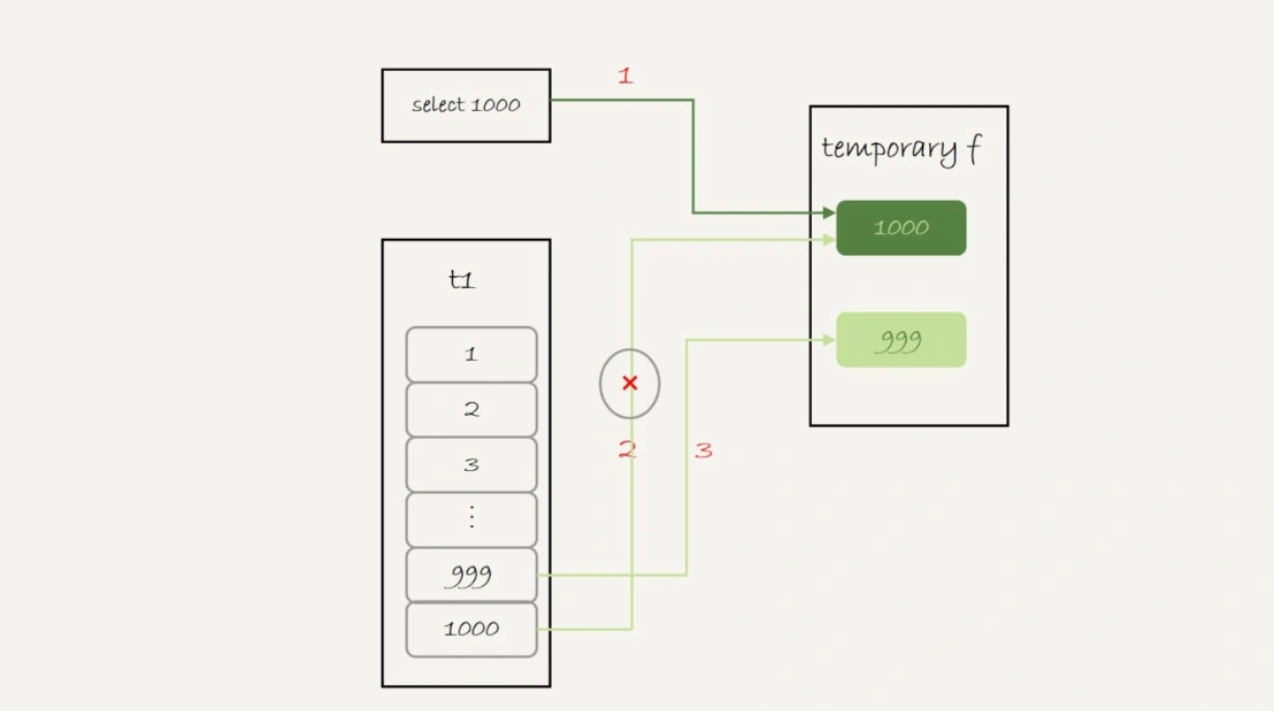
可以看到,这里的内存临时表起到了暂存数据的作用,而且计算过程还用上了临时表主键 id 的唯一性约束,实现了 union 的语义。
顺便提一下,如果把上面这个语句中的 union 改成 union all 的话,就没有了“去重”的语义。这样执行的时候,就依次执行子查询,得到的结果直接作为结果集的一部分,发给客户端。因此也就不需要临时表了。

可以看到,第二行的 Extra 字段显示的是 Using index,表示只使用了覆盖索引,没有用临时表了。