数据分片的目的
主要解决的问题是:单台服务器存储和性能限制。
数据分片需要考虑的要点
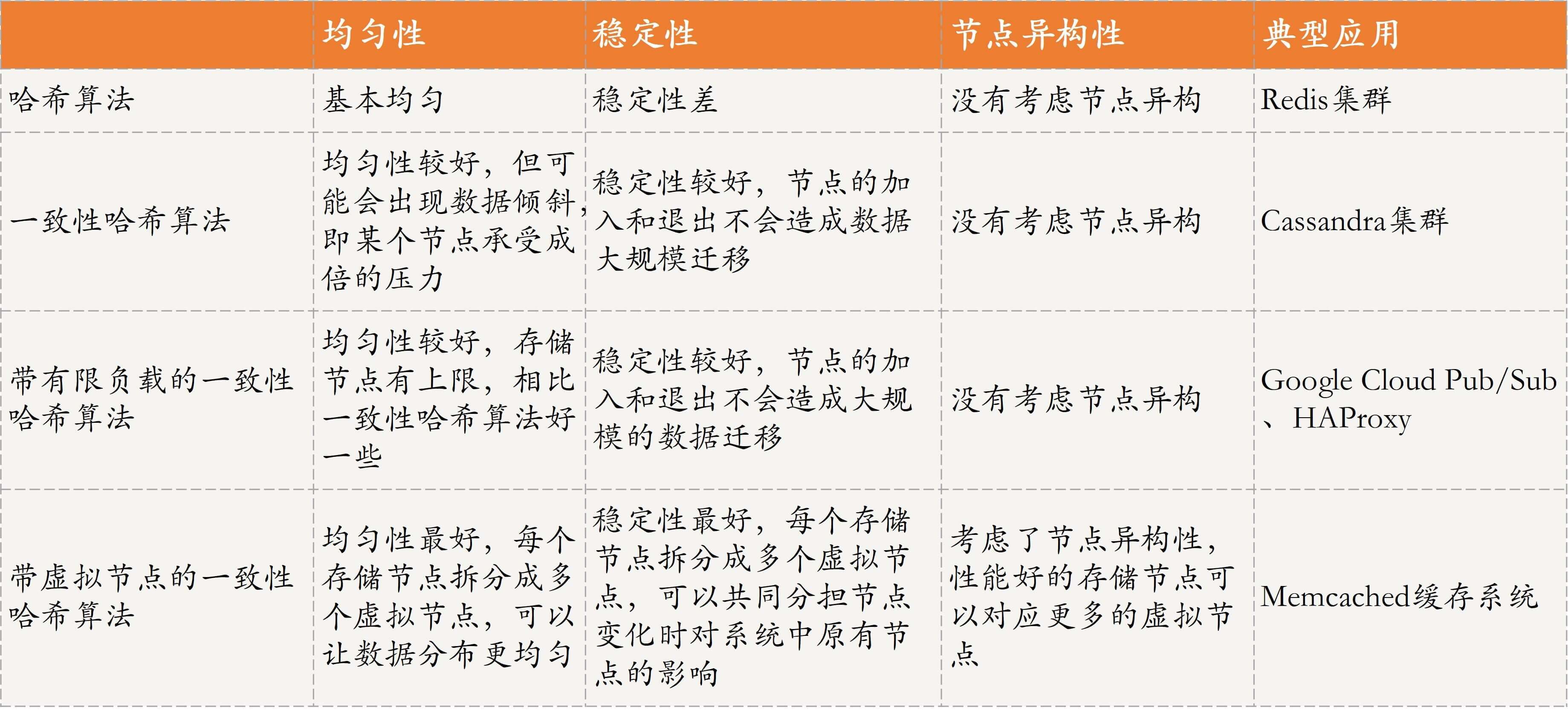
- 数据均匀 —— 每个节点数据量差不多,每个节点的用户访问也差不多,注意分配策略,避免导致单节点访问过多,单节点访问过少的情况。
- 从数据迁移成本的维度考虑,当存储节点出现故障需要移除或者扩增时,数据按照分布规则得到的结果应该尽量保持稳定,不要出现大范围的数据迁移。
- 从节点异构性的维度考虑,不同存储节点的硬件配置可能差别很大。比如,有的节点硬件配置很高,可以存储大量数据,也可以承受更多的请求;但,有的节点硬件配置就不怎么样,存储的数据量不能过多,用户访问也不能过多。
- 隔离故障域,是为了保证数据的可用和可靠性。比如,我们通常通过备份来实现数据的可靠性。但如果每个数据及它的备份,被分布到了同一块硬盘或节点上,就有点违背备份的初衷了。
- 性能稳定性是指,数据存储和查询的效率要有保证,不能因为节点的添加或者移除,造成存储或访问性能的严重下降。
数据分片的方案
范围分片
在这种分片策略中,根据特定字段的值范围来分配数据到不同的分片。例如,用户 ID 从 0 到 999 的记录存储在一个分片上,而 1000 到 1999 的记录存储在另一个分片上。这种方法的优点是查询容易实现,但缺点是可能导致某些分片负载过重,因为数据分布可能不均匀。
另外,比如在商品场景下,每个商品是存在多级类别目录的。在根据类别目录分片时,可以按照一、二、三级类目进行灵活分片。对于京东强势的 3C 品类,可以按照 3C 的三级品类设置分片;对于弱势品类,可以先按照一级品类进行分片,这样会让分片间的数据更加平衡。
优点:方案简单,扩容时方便。
缺点:代码侵占性高。
哈希分片
哈希分片使用哈希函数将数据映射到不同的分片。通常是对选定的关键字应用哈希算法,然后根据哈希结果决定数据应存放在哪个分片。这种方法有助于更均匀地分布数据和请求,从而减轻单个分片的负担。但是,它可能会使得范围查询变得复杂,因为同一范围的数据可能被分散到了多个分片上。
优点:分片逻辑简单,容易实现。
缺点:扩容时数据迁移困难。
一致性哈希分片
- 一致性哈希
- 一致性哈希同样是采用哈希函数,进行两步哈希:
- 对存储节点进行哈希计算,也就是对存储节点做哈希映射;
- 当对数据进行存储或访问时,首先对数据进行映射得到一个结果,然后找到比该结果大的第一个存储节点,就是该数据应该存储的地方。我会在下面的内容中,与你详细介绍其中的原理。
- 当节点加入或退出时,仅影响该节点在哈希环上顺时针相邻的后继节点。比如,当 Node2 发生故障需要移除时,由于 Node3 是 Node2 顺时针方向的后继节点,本应存储到 Node2 的数据就会存储到 Node3 中,其他节点不会受到影响,因此不会发生大规模的数据迁移。所以,一致性哈希方法比较适合同类型节点、节点规模会发生变化的场景。目前,Cassandra 就使用了一致性哈希方法。
- 一致性哈希的问题:单个故障后,后继节点承担更大的流量,可能导致节点崩溃,进而继续影响后续节点。
- 对于 Redis 来说,使用一致性哈希有一个问题,节点过期问题。节点崩溃再恢复后,中间对后继节点进行了修改,导致节点恢复后为脏数据。可能需要设置过期时间或者清空数据?
- 一致性哈希同样是采用哈希函数,进行两步哈希:
- 带有限负载的一致性哈希
- 原理:给每个存储节点设置了一个存储上限值来控制存储节点添加或移除造成的数据不均匀。当数据按照一致性哈希算法找到相应的存储节点时,要先判断该存储节点是否达到了存储上限;如果已经达到了上限,则需要继续寻找该存储节点顺时针方向之后的节点进行存储。可以阅读“Consistent Hashing with Bounded Loads”这篇论文。
- 带有限负载的一致性哈希方法比较适合同类型节点、节点规模会发生变化的场景。目前,在 Google Cloud Pub/Sub、HAProxy 中已经实现该方法,应用于 Google、Vimeo 等公司的负载均衡项目中。
- 如果使用这种哈希方法,那么在查询数据的时候该怎么办呢?
- 如果对应节点查询不存在,那么可能需要访问下一个节点,判断是否存在数据。这种方式类似于,解决哈希冲突时,通过开放地址法来存储数据,并在查询时若对应位置有数据但不一致时,遍历下一个可能的位置。
- 但是上面方法开销比较大,或许也可以考虑在哈希命中节点上额外添加一个索引表,用以记录命中到该节点上的数据存储在哈希环上的位置。这样在通过一致性哈希计算出命中的节点后,只需要再查询这个节点上的索引表就可以找到实际的存储节点了。当然这种复杂度也就更高了。
- 带虚拟节点的一致性哈希
- Node1 性能最差,Node2 性能一般,Node3 性能最好。以 Node1 的性能作为参考基准,Node2 是 Node1 的 2 倍,Node3 是 Node1 的 3 倍。因此,Node1 对应一个虚拟节点 Node1_1,Node2 对应 2 个虚拟节点 Node2_1 和 Node2_2,Node3 对应 3 个虚拟节点 Node3_1、Node3_2 和 Node3_3。虚拟节点 Node1_1、Node2_1、Node2_2、Node3_1、Node3_2、Node3_3 的哈希值,分别为 100、200、300、400、500、600。
- 带虚拟节点的一致性哈希方法比较适合异构节点、节点规模会发生变化的场景。
- 这种方法引入了虚拟节点,增加了节点规模,从而增加了节点的维护和管理的复杂度,比如新增一个节点或一个节点故障时,对应到虚拟节点构建的哈希环上需要新增和删除多个节点,数据的迁移等操作相应地也会很复杂。
- 哈希算法的对比 算法对比|400。
{kind=link}
地理位置分片
这种主要是针对特殊场景进行处理:区域延迟高 + 不同国家区域可存储数据不同。
动态分片
动态分片允许系统根据当前的工作负载情况自动调整分片的数量和大小。这对于需要适应不断变化的数据量和服务需求的应用程序非常有用。不过,实施动态分片增加了系统的复杂度,因为它涉及到实时监控和迁移数据的能力。
搭建一个分片元数据服务。在请求数据的时候,先访问该服务获得真实数据所在的节点,后续再去该节点上去获取数据。当然这种增加了系统的复杂性、开发和维护成本等,需要进行权衡。
数据分区和数据分片的区别
- 数据分区是 Partitioning。比如 DB 分区,按照月为单位进行数据分区,一般是同一个机器上的不同表。提高查询性能,降低单一数据表的查询时间,简化维护操作(如备份、恢复),以及提升可扩展性。
- 数据分片是 Sharding。数据分散到多个独立的数据库实例或节点上,每份数据是独立数据库。减轻单一数据库的压力,并改善读写性能。