来源于《软件架构设计:大型网站技术架构与业务架构融合之道》
Redolog 逻辑与物理结构
从逻辑上来讲,日志就是一个无限延长的字节流,从数据库安装好并启动的时间点开始,日志便源源不断地追加,永无结束。
但从物理上来讲,日志不可能是一个永不结束的字节流,日志的物理结构和逻辑结构,有两个非常显著的差异点:
- 磁盘的读取和写入都不是按一个个字节来处理的,磁盘是“块”设备,为了保证磁盘的 I/O 效率,都是整块地读取和写入。对于 Redo Log 来说,就是 Redo Log Block,每个 Redo Log Block 是 512 字节。为什么是 512 字节呢?因为早期的磁盘,一个扇区(最细粒度的磁盘存储单位)就是存储 512 字节数据。
- 日志文件不可能无限制膨胀,过了一定时期,之前的历史日志就不需要了,通俗地讲叫“归档”,专业术语是 Checkpoint。所以 Redo Log 其实是一个固定大小的文件,循环使用,写到尾部之后,回到头部覆写(实际 Redo Log 是一组文件,但这里就当成一个大文件,不影响对原理的理解)。之所以能覆写,因为一旦 Page 数据刷到磁盘上,日志数据就没有存在的必要了。
图 6-8 展示了 Redo Log 逻辑与物理结构的差异,LSN(Log Sequence Number)是逻辑上日志按照时间顺序从小到大的编号。在 InnoDB 中,LSN 是一个 64 位的整数,取的是从数据库安装启动开始,到当前所写入的总的日志字节数。实际上 LSN 没有从 0 开始,而是从 8192 开始,这个是 InnoDB 源代码里面的一个常量 LOG_START_LSN。因为事务有大有小,每个事务产生的日志数据量是不一样的,所以日志是变长记录,因此 LSN 是单调递增的,但肯定不是呈单调连续递增。
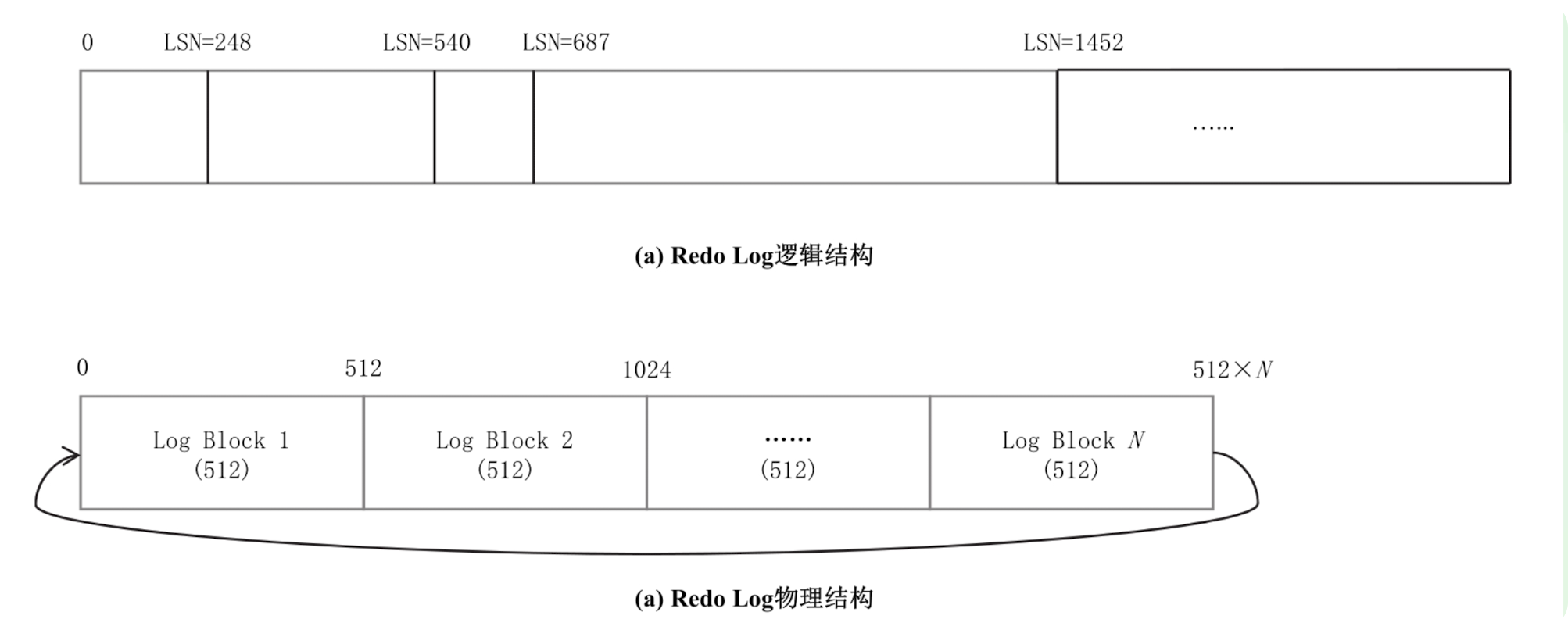
物理上面,一个固定的文件大小,每 512 个字节一个 Block,循环使用。显然,很容易通过 LSN 换算出所属的 Block。反过来,给定 Redo Log,也很容易算出第一条日志在什么位置。假设在 Redo Log 中,从头到尾所记录的 LSN 依次如下所示:
(200,289,378,478,30,46,58,69,129)
很显然,第 1 条日志是 30,最后 1 条日志是 478,30 以前的已经被覆盖。
Physiological Logging
知道了 Redo Log 的整体结构,下面进一步来看每个 Log Block 里面 Log 的存储格式。这个问题很关键,是数据库事务实现的一个核心点。
- 记法 1。类似 Binlog 的 statement 格式,记原始的 SQL 语句,insert/delete/update。
- 记法 2。类似 Binlog 的 RAW 格式,记录每张表的每条记录的修改前的值、修改后的值,类似(表,行,修改前的值,修改后的值)。
- 记法 3。记录修改的每个 Page 的字节数据。由于每个 Page 有 16KB,记录这 16KB 里哪些部分被修改了。一个 Page 如果被修改了多个地方,就会有多条物理日志,如下所示:
(Page ID,offset1,len1,改之前的值,改之后的值)
(Page ID,offset2,len2,改之前的值,改之后的值)
前两种记法都是逻辑记法;第三种是物理记法。Redo Log 采用了哪种记法呢?它采用了逻辑和物理的综合体,就是先以 Page 为单位记录日志,每个 Page 里面再采取逻辑记法(记录 Page 里面的哪一行被修改了)。这种记法有个专业术语,叫 Physiological Logging。
要搞清楚为什么要采用 Physiological Logging,就得知道逻辑日志和物理日志的对应关系:
- 一条逻辑日志可能产生多个 Page 的物理日志。比如往某个表中插入一条记录,逻辑上是一条日志,但物理上可能会操作两个以上的 Page?为什么呢,因为一个表可能有多个索引,每个索引都是一颗 B+树,插入一条记录,同时更新多个索引,自然可能修改多个 Page。
如果 Redo Log 采用逻辑日志的记法,一条记录牵涉的多个 Page 写到一半系统宕机了,要恢复的时候很难知道到底哪个 Page 写成功了,哪个失败了。 - 即使 1 条逻辑日志只对应一个 Page,也可能要修改这个 Page 的多个地方。因为一个 Page 里面的记录是用链表串联的,所以如果在中间插入一条记录,不仅要插入数据,还要修改记录前后的链表指针。对应到 Page 就是多个位置要修改,会产生多条物理日志。
所以纯粹的逻辑日志宕机后不好恢复;物理日志又太大,一条逻辑日志就可能对应多条物理日志。Physiological Logging 综合了两种记法的优点,先以 Page 为单位记录日志,在每个 Page 里面再采用逻辑记法。
I/O 写入的原子性(Double Write)
要实现事务的原子性,先得考虑磁盘 I/O 的原子性。一个 Log Block 是 512 个字节。假设调用操作系统的一次 Write,往磁盘上写入一个 Log Block(512 个字节),如果写到一半机器宕机后再重启,请问写入成功的字节数是 0,还是 [0,512] 之间的任意一个数值?
这个问题的答案并不唯一,可能与操作系统底层和磁盘的机制有关,如果底层实现了 512 个字节写入的原子性,上层就不需要做什么事情;否则,在上层就需要考虑这个问题。假设底层没有保证 512 个字节的原子性,可以通过在日志中加入 checksum 解决。通过 checksum 能判断出宕机之后重启,一个 Log Block 是否完整。如果不完整,就可以丢弃这个 LogBlock,对日志来说,就是做截断操作。
除了日志写入有原子性问题,数据写入的原子性问题更大。一个 Page 有 16KB,往磁盘上刷盘,如果刷到一半系统宕机再重启,请问这个 Page 是什么状态?在这种情况下,Page 既不是一个脏的 Page,也不是一个干净的 Page,而是一个损坏的 Page。既然已经有 Redo Log 了,不能用 Redo Log 恢复这个 Page 吗?
因为 Redo Log 也恢复不了。因为 Redo Log 是 Physiological Logging,里面只是一个对 Page 的修改的逻辑记录,Redo Log 记录了哪个地方修改了,但不知道哪个地方损坏了。另外,即使为这个 Page 加了 checksum,也只能判断出 Page 损坏了,只能丢弃,但无法恢复数据。有两个解决办法:
(1)让硬件支持 16KB 写入的原子性。要么写入 0 个字节,要么 16KB 全部成功。
(2)Double write。把 16KB 写入到一个临时的磁盘位置,写入成功后再拷贝到目标磁盘位置。
这样,即使目标磁盘位置的 16KB 因为宕机被损坏了,还可以用备份去恢复。
Redo Log Block 结构
Log Block 还需要有 Check sum 的字段,另外还有一些头部字段。事务可大可小,可能一个 Block 存不下产生的日志数据,也可能一个 Block 能存下多个事务的数据。所以在 Block 里面,得有字段记录这种偏移量。
图 6-9 展示了一个 Redo Log Block 的详细结构,头部有 12 字节,尾部 Check sum 有 4 个字节,所以实际一个 Block 能存的日志数据只有 496 字节。
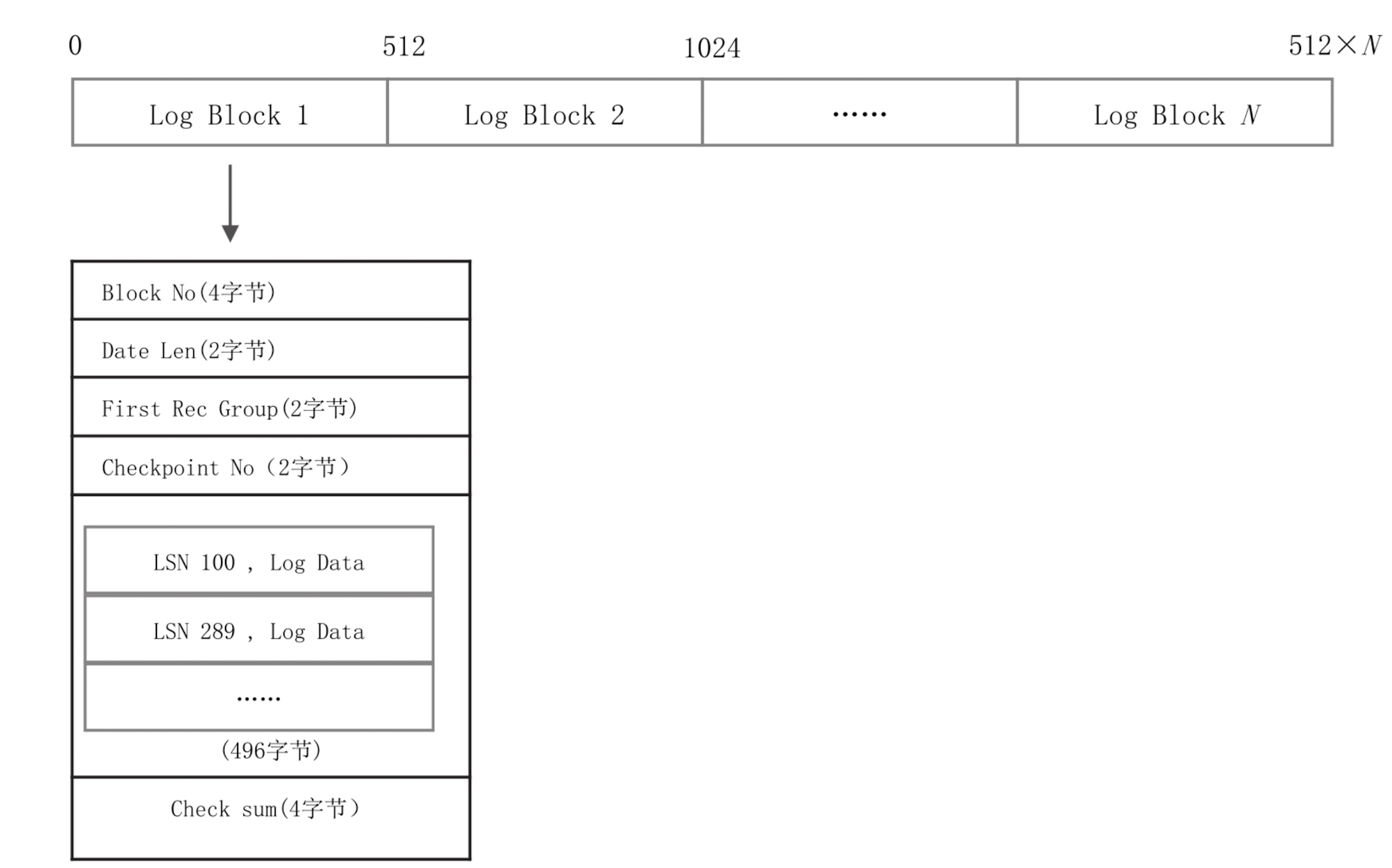
头部 4 个字段的含义分别如下:
- Block No:每个 Block 的唯一编号,可以由 LSN 换算得到。
- Date Len:该 Block 中实际日志数据的大小,可能 496 字节没有存满。
- First Rec Group:该 Block 中第一条日志的起始位置,可能因为上一条日志很大,上一个 Block 没有存下,日志的部分数据到了当前的 Block。如果 First Rec Group=Data Len,则说明上一条日志太大,大到横跨了上一个 Block、当前 Block、下一个 Block,当前 Block 中没有新日志。
- Checkpoint No:当前 Block 进行 Check point 时对应的 LSN(下文会专门讲 Checkpoint)。
事务、LSN 与 Log Block 的关系
知道了 Redo Log 的结构,下面从一个事务的提交开始分析,看事务和对应的 Redo Log 之间的关联关系。假设有一个事务,伪代码如下:

其产生的日志,如图 6-10 所示。应用层所说的事务都是“逻辑事务”,具体到底层实现,是“物理事务”,也叫作 Mini Transaction(Mtr)。在逻辑层面,事务是三条 SQL 语句,涉及两张表;在物理层面,可能是修改了两个 Page(当然也可能是四个 Page,五个 Page……),每个 Page 的修改对应一个 Mtr。每个 Mtr 产生一部分日志,生成一个 LSN。
这个“逻辑事务”产生了两段日志和两个 LSN。分别存储到 Redo Log 的 Block 里,这两段日志可能是连续的,也可能是不连续的(中间插入的有其他事务的日志)。所以,在实际磁盘上面,一个逻辑事务对应的日志不是连续的,但一个物理事务(Mtr)对应的日志一定是连续的(即使横跨多个 Block)。
图 6-11 展示了两个逻辑事务,其对应的 Redo Log 在磁盘上的排列示意图。可以看到,LSN 是单调递增的,但是两个事务对应的日志是交叉排列的。