几个方面去进行思考和分析:
- 数据如何复制?
- 各个节点的职责是什么?
- 如何应对复制延迟?
- 如何应对复制中断?
- 一主多备份
- 主机如何将数据复制给备机
- 备机如何检测主机状态
- 主机故障后,如何决定新的主机
- 多主的分区存储
- 数据分散集群的复杂点在于如何将数据分配到不同的服务器上,均衡、容错、可伸缩
常见的高可用存储架构有主备、主从、主主、集群、分区,每一种又可以根据业务的需求进行一些特殊的定制化功能,由此衍生出更多的变种。
主备主从架构
主备架构:备机只进行备份,无业务读写。主备切换需要人工。优点:简单、双方只需要数据复制。缺点:无读写操作,资源浪费;切换需要人工操作。内部的后台管理系统使用主备复制架构的情况会比较多,人工进行切换+丢数据时的补全。
主从架构:从机进行备份+读操作。优点:主机故障仍可读操作,相较于主备发挥了硬件性能。缺点:客户端需要感知主从关系,不同操作发送到不同机器上;主从复制延迟可能比较大;故障需要人工干预。写少读多(10 倍、100 倍)的业务使用主从复制的存储架构比较多。
双机切换架构
架构设计技术点
- 主备间状态判断。主要包括两方面:状态传递的渠道,以及状态检测的内容。
- 状态传递的渠道:是相互间互相连接,还是第三方仲裁?
- 状态检测的内容:例如机器是否掉电、进程是否存在、响应是否缓慢等。
- 切换决策。主要包括几方面:切换时机、切换策略、自动程度。
- 切换时机:什么情况下备机应该升级为主机?是机器掉电后备机才升级,还是主机上的进程不存在就升级,还是主机响应时间超过 2 秒就升级,还是 3 分钟内主机连续重启 3 次就升级等。
- 切换策略:原来的主机故障恢复后,要再次切换,确保原来的主机继续做主机,还是原来的主机故障恢复后自动成为新的备机?
- 自动程度:切换是完全自动的,还是半自动的?例如,系统判断当前需要切换,但需要人工做最终的确认操作(例如,单击一下“切换”按钮)。
- 数据冲突解决
- 当原有故障的主机恢复后,新旧主机之间可能存在数据冲突。例如,用户在旧主机上新增了一条 ID 为 100 的数据,这个数据还没有复制到旧的备机,此时发生了切换,旧的备机升级为新的主机,用户又在新的主机上新增了一条 ID 为 100 的数据,当旧的故障主机恢复后,这两条 ID 都为 100 的数据,应该怎么处理?
常见架构
根据状态传递渠道的不同,常见的主备切换架构有三种形式:互连式、中介式和模拟式。
互连式
在主备复制的架构基础上,主机和备机多了一个“状态传递”的通道,这个通道就是用来传递状态信息的。这个通道的具体实现可以有很多方式:
- 可以是网络连接(例如,各开一个端口),也可以是非网络连接(用串口线连接)。
- 可以是主机发送状态给备机,也可以是备机到主机来获取状态信息。
- 可以和数据复制通道共用,也可以独立一条通道。
- 状态传递通道可以是一条,也可以是多条,还可以是不同类型的通道混合(例如,网络 + 串口)。
为了充分利用切换方案能够自动决定主机这个优势,客户端这里也会有一些相应的改变,常见的方式有:
- 为了切换后不影响客户端的访问,主机和备机之间共享一个对客户端来说唯一的地址。例如虚拟 IP,主机需要绑定这个虚拟的 IP。
- 客户端同时记录主备机的地址,哪个能访问就访问哪个;备机虽然能收到客户端的操作请求,但是会直接拒绝,拒绝的原因就是“备机不对外提供服务”。
互连式主备切换主要的缺点在于:
- 如果状态传递的通道本身有故障(例如,网线被人不小心踢掉了),那么备机也会认为主机故障了从而将自己升级为主机,而此时主机并没有故障,最终就可能出现两个主机。
- 虽然可以通过增加多个通道来增强状态传递的可靠性,但这样做只是降低了通道故障概率而已,不能从根本上解决这个缺点,而且通道越多,后续的状态决策会更加复杂,因为对备机来说,可能从不同的通道收到了不同甚至矛盾的状态信息。
中介式
主机和备机不再通过互联通道传递状态信息,而是都将状态上报给中介这一角色。单纯从架构上看,中介式似乎比互连式更加复杂了,首先要引入中介,然后要各自上报状态。然而事实上,中介式架构在状态传递和决策上却更加简单了,
连接管理更简单:主备机无须再建立和管理多种类型的状态传递连接通道,只要连接到中介即可,实际上是降低了主备机的连接管理复杂度。
状态决策更简单:主备机的状态决策简单了,无须考虑多种类型的连接通道获取的状态信息如何决策的问题,只需要按照下面简单的算法即可完成状态决策。(相当于有第三个人帮忙决策了,主备机可以不用关注那么多事情了)
- 无论是主机还是备机,初始状态都是备机,并且只要与中介断开连接,就将自己降级为备机,因此可能出现双备机的情况。
- 主机与中介断连后,中介能够立刻告知备机,备机将自己升级为主机。
- 如果是网络中断导致主机与中介断连,主机自己会降级为备机,网络恢复后,旧的主机以新的备机身份向中介上报自己的状态。
- 如果是掉电重启或者进程重启,旧的主机初始状态为备机,与中介恢复连接后,发现已经有主机了,保持自己备机状态不变。
- 主备机与中介连接都正常的情况下,按照实际的状态决定是否进行切换。例如,主机响应时间超过 3 秒就进行切换,主机降级为备机,备机升级为主机即可。
这种简单的优点的代价就在于如何实现中介本身的高可用,于是又要设计中介的高可用方案…… 中介节点的高可用可以通过 Zookeeper 等来解决。
模拟式
备机通过模拟的读写操作来探测主机的状态,然后根据读写操作的响应情况来进行状态决策。
模拟式切换与互连式切换相比,优点是实现更加简单,因为省去了状态传递通道的建立和管理工作。
简单既是优点,同时也是缺点。因为模拟式读写操作获取的状态信息只有响应信息(例如,HTTP 404,超时、响应时间超过 3 秒等),没有互连式那样多样(除了响应信息,还可以包含 CPU 负载、I/O 负载、吞吐量、响应时间等),基于有限的状态来做状态决策,可能出现偏差。
主主架构
主主架构:两台主机,互相复制,都提供读写能力,客户端操作发送到任意主机上。虽然不需要各种管理等,但是并不是所有都可以复制的,比如商品剩余库存值、用户 ID。
针对用户 ID,之前看到的方法是,数据库的自增值设置为 2,一个主机 ID 为奇数,一个主机 ID 是偶数来解决。
主主复制架构对数据的设计有严格的要求,一般适合于那些临时性、可丢失、可覆盖的数据场景。例如,用户登录产生的 session 数据(可以重新登录生成)、用户行为的日志数据(可以丢失)、论坛的草稿数据(可以丢失)等。
感觉这些适用的场景也可以反过来,当在这场景下,可以选择这样的架构。
数据集群
数据集中集群
一主多从、一主多备的架构。虽然形式和两台服务器类似,但是复杂度会变的更高。
- 主机如何将数据复制给所有的备机。复制多份会增加主机的复制压力,不同复制通道也会导致备库的数据不一致。
- 备机如何检测主机状态。不同的备机判断的结果可能是不同的。
- 主机故障后,如何决定新的主机。
目前开源的数据集中集群以 ZooKeeper 为典型,ZooKeeper 通过 ZAB 算法来解决上述提到的几个问题,但 ZAB 算法的复杂度是很高的。
怎么感觉这部分有点类似于分布式数据库的内容。
另外,复杂度的问题,可以基于解决方案发挥了什么作用来反向思考。
数据分散集群
多个服务器组成一个集群,每台服务器都会负责存储一部分数据;同时,为了提升硬件利用率,每台服务器又会备份一部分数据。复杂点在于,数据分配的问题。
- 均衡性。算法需要保证服务器上的数据分区基本是均衡的,不能存在某台服务器上的分区数量是另外一台服务器的几倍的情况。
- 容错性。当出现部分服务器故障时,算法需要将原来分配给故障服务器的数据分区分配给其他服务器。
- 可伸缩性。当集群容量不够,扩充新的服务器后,算法能够自动将部分数据分区迁移到新服务器,并保证扩容后所有服务器的均衡性。
数据分散集群需要一个类似于服务器去执行负责执行数据分配算法。
Hadoop 的实现就是独立的服务器负责数据分区的分配,这台服务器叫作 Namenode。Hadoop 的数据分区管理架构如下:
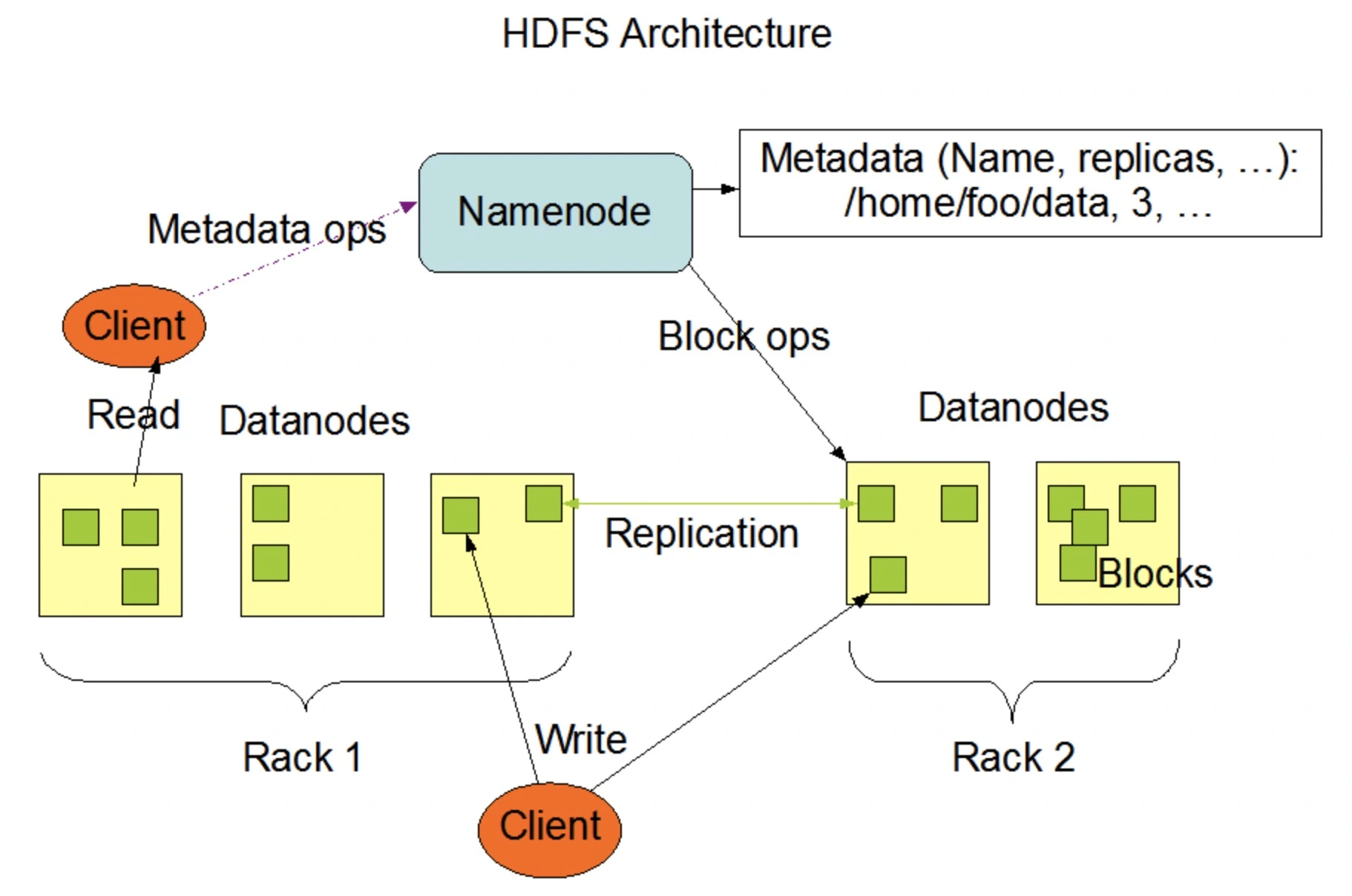
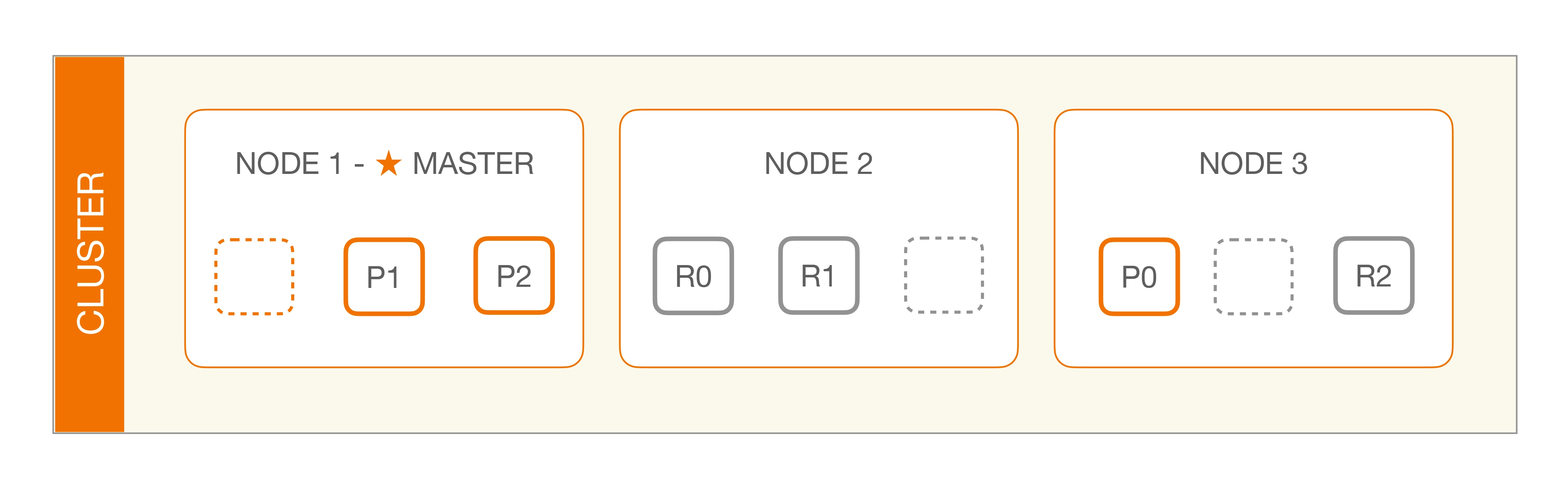
与 Hadoop 不同的是,Elasticsearch 集群通过选举一台服务器来做数据分区的分配,叫作 master node,其数据分区管理架构是:
数据分区
前面考虑的情况仅仅考虑了单台服务器故障的问题,但是如果一整个机房故障了,比如城市停电、光缆被挖等情况,还需要基于地理级别的故障来设计高可用架构,即数据分区的背景。数据分区指将数据按照一定的规则进行分区,不同分区分布在不同的地理位置上,每个分区存储一部分数据,通过这种方式来规避地理级别的故障所造成的巨大影响。
- 数据量。越大的数据量,数据分区的分配规则越复杂,考虑内容越多。具体表现:
- 800 台服务器里面可能每周都有一两台服务器故障,定位故障服务器的难度增加。
- 新增服务器需要修改分配规则,可能会影响 800 台服务器运行。
- 分区规则需要考虑地理容灾。
- 分区规则。不同的分区规则,包括洲际分区、国家分区、城市分区。具体采取哪种或者哪几种规则,需要综合考虑业务范围、成本等因素。前两者基本上都是为了当地国家进行服务,因为延迟较高,在线同步不现实。城市分区适合作为容灾,延迟低,可以满足业务异地多活之类的需求。
- 复制规则。复制规则有三种:集中式、互备式和独立式。
- 集中式:总的备份中心。北京、上海、广州分区都复制到西安中心。优缺点:(1)简单、分区互不影响 (2)扩展容易 (3)成本较高,需要建设一个独立的备份中心。
- 互备式:每个分区备份另外一个分区的数据,类似于 ElasticSearch、Kafka 那种,存有其他区的数据备份。优缺点:(1)复杂,需要交互 (2)扩展麻烦 (3)成本低,利用当前设备。(这里的成本,应该可以理解为机房的概念?而不是单纯机器价格,还有数据中心这个房子设施的租房等价格)
- 独立式:每个分区有不同的备份中心。北京到廊坊,上海到苏州,广州到汕头。优缺点:(1)简单、分区互不影响 (2)扩展容易 (3)成本高