可预估数据量场景
游戏创建房间场景
- 根据一个服务器可以容纳多少房间上线来限制能服务多少用户。
- 如何评估一个服务器支持多少人同时在线呢?压测获得单台服务器在线人数,预估带宽和服务器资源,算出一个集群能承担多少人同时在线。
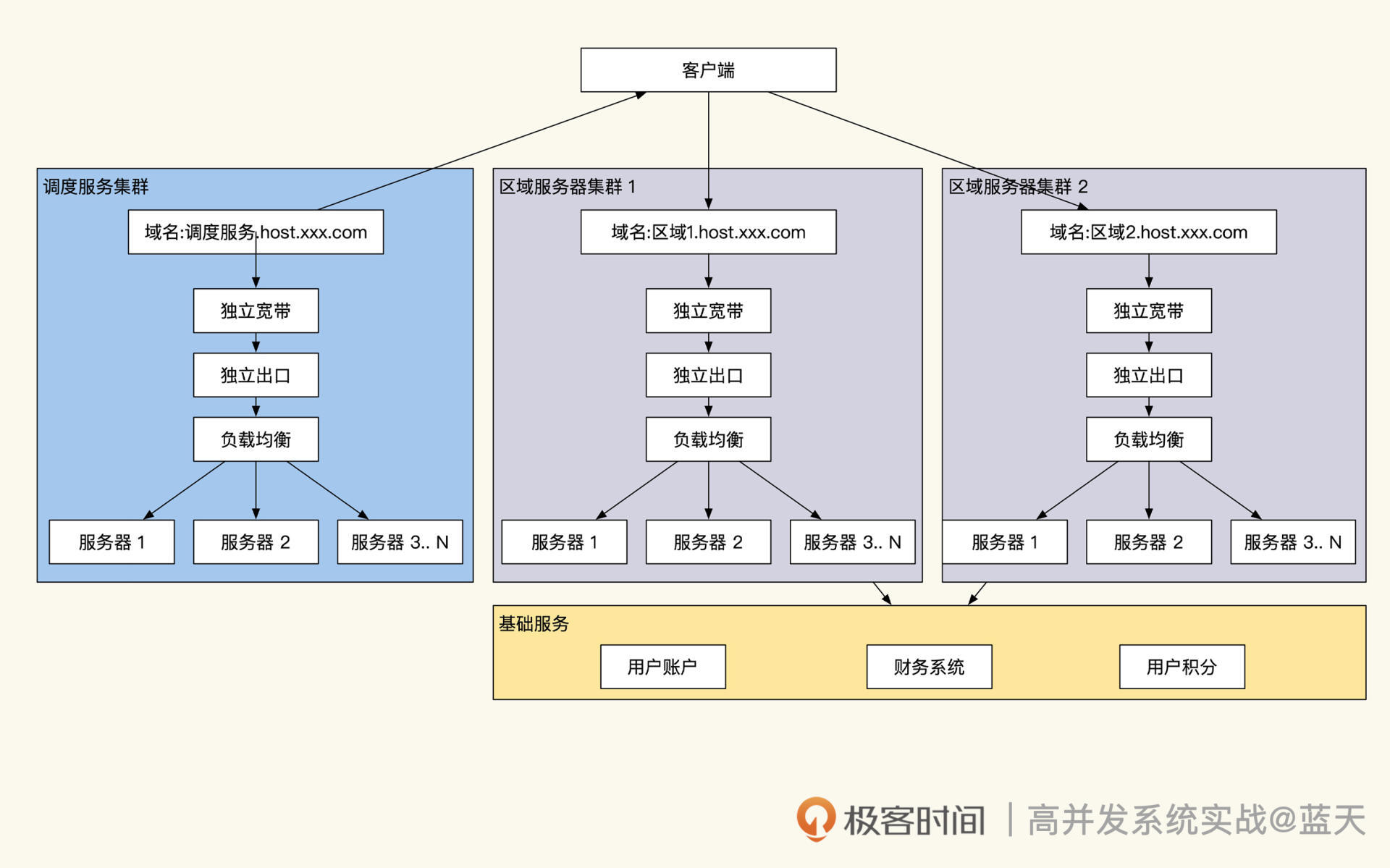
- 当创建房间时,客户端请求调度服务来进行调度的。调度服务器定期接收各组服务器的成员在线人数情况,进而评估调配多少用户进入不同集群。客户端收到调度后,拿着调度服务给的 token 去不同区域申请创建房间。调度服务会在本地集群内维护这个房间的列表和信息,提供给其他要加入游戏的玩家展示。而加入的玩家同样会接入对应房间的区域服务器,与房主及同房间玩家进行实时互动。
不可预估数据量场景
全球直播场景
- 根据主播过往或者同级别主播来推测用户量,根据结果安排到相对空闲的服务器群组中。同时提前准备一些调度工具,如控制曝光度等来延缓用户进入直播,为动态扩容提供时间。
直播中的弹幕场景
- 聊天内容放入到 MQ 中
- 点赞或重复性内容通过大数据计算进行数据压缩
- 数据会分发到多个聊天内容分发服务器上,客户端通过长链接收到消息更新通知,到指定的内容分发服务器中批量拉取数据,然后根据时间顺序进行重放
- 若数据量/用户量不大的情况下,则长连接实时互动即可
最后一部分让我想到了如何设计微博 Feed 流系统? 的情况。粉丝数量大的博主 & 活跃用户,采用推送的方式;粉丝数量大的博主 & 非活跃用户,采用拉取的方式。针对不同的群体采用推 or 拉的方式。

直播中的题目答题场景
- 主播某时刻将题目广播给所有用户,客户端收到消息后拉取题目。
- 10w 人数在线,10w 人同时拉取,需要投入大量服务器和带宽,性价比不高。
- 将数据静态化,通过 CDN 来阻挡流量。进一步,客户端可随机延迟几秒发送请求。
- 客户端失败后,不要频繁重试,加大压力,可以对重试时间采取退火算法。
- 如果可以,将题目提前交给客户端做预加载下载,减少瞬时压力。
- 抢答延迟,通过倒数 5s 后弹出题目等机制,让用户能“准时”收到题目进行答题。
- 非抢答场景,可以本地进行预判卷,再返回给服务端。服务端后续也需要进行校验。
直播点赞场景
- 客户端无需实时提交用户所有交互,可以本地先展示,然后异步提交。
- 客户端提交时可以进行数据合并,如 3s 点赞 10 次,连续打赏 100 个礼物。
- 请求合并是一种常见的减少请求数的方式,如秒杀时的多次点击,其实只有第一次请求是有效的。
- 服务端通过多级缓存来缓解流量压力。通过第一层写缓存本地的实时汇总来缓解大量用户的请求,将更新数据周期性地汇总后,提交到二级写缓存。二级汇总所在分片的所有上层服务数值后,最终汇总同步给核心缓存服务。接着,通过核心缓存把最终结果汇总累加起来。最后通过主从复制到多个子查询节点服务,供用户查询汇总结果。
- 微博是微博是Redis重度用户,后来因为点赞数据量太大,在Redis中缓存点赞数内存浪费严重(可以回顾上一节课 jmalloc 兄弟算法的内容),改为自行实现点赞服务来节省内存。

直播打赏消费场景
- 这种场景需要提供事务一致性。
- 数据切片 + 用户 ID 哈希拆分。
- 另一种方式树形热迁移切片法,这是一种类似虚拟桶的方式。比如我们将全量数据拆分成 256 份,一份代表一个桶,16 个服务器每个分 16 个桶,当我们个别服务器压力过大的时候,可以给这个服务器增加两个订阅服务器去做主从同步,迁移这个服务器的 16 个桶的数据。待同步迁移成功后,将这个服务器的请求流量拆分转发到两个 8 桶服务器,分别请求这两个订阅服务器继续对外服务,原服务器摘除回收即可。服务切换成功后,由于是全量迁移,这两个服务同时同步了不属于自己的 8 个桶数据,这时新服务器遍历自己存储的数据,删除掉不属于自己的数据即可。当然也可以在同步 16 桶服务的数据时,过滤掉这些数据,这个方法适用于 Redis、MySQL 等所有有状态分片数据服务。这个服务的难点在于请求的客户端不直接请求分片,而是通过代理服务去请求数据服务,只有通过代理服务才能够动态更新调度流量,实现平滑无损地转发流量。