etcd 写请求

首先,client 端通过负载均衡算法选择一个 etcd 节点,发起 gRPC 调用。然后 etcd 节点收到请求后经过 gRPC 拦截器、Quota 模块后,进入 KVServer 模块,KVServer 模块向 Raft 模块提交一个提案。例如,提案内容为“大家好,请使用 put 方法执行一个 key 为 hello,value 为 world 的命令”。
随后此提案通过 RaftHTTP 网络模块转发、经过集群多数节点持久化后,状态会变成已提交,etcdserver 从 Raft 模块获取已提交的日志条目,传递给 Apply 模块,Apply 模块通过 MVCC 模块执行提案内容,更新状态机。
Quota 模块
etcdserver: mvcc: database space exceeded 错误
- 错误概念:它是指当前 etcd db 文件大小超过了配额,当出现此错误后,你的整个集群将不可写入,只读。
- 错误原因:默认 db 配额仅 2G,数据超过限额。业务数据过多,或者 MVCC 未配置压缩策略导致超限。
Quota 工作流程
当 etcd server 收到写请求时,会检查 etcd db 大小加上请求的 key-value 大小之和是否超过了配额 quota-backend-bytes。当超过,则发出 alarm 告警请求,告警请求类型 NO SPACE,并通过 Raft 日志同步给其他节点,告知 db 无空间,并持久化到 db 中,后续将处于只读状态。
解决超出配额的方案
- 首先,调大配额
quota-backend-bytes。etcd 社区建议不超过 8G。注意,‘0’代表默认 2GB,负数代表禁用配额功能,可能会导致 db 大小失控,导致性能下降。 - 其次,发送取消告警的命令
etcdctl alarm disarm,消除告警。否则 Apply 模块在执行命令时会检查是否存在 NO SPACE 告警,否则拒绝写入。 - 然后,检查压缩配置 compact 是否开启和配置合理。
KVServer 模块
Preflight Check
在提交到 Raft 模块前会进行一系列检查。
- (1) 限速检查。若
committed index - applyied index > 5000,即状态机应用的索引比已提交的日志索引落后太多,会进行限速,返回etcdserver: too many requests错误给客户端。 - (2) 鉴权检查。若使用密码鉴权、请求中携带了 token。若 token 无效,则返回
auth: invalid auth token错误。 - (3) 大包检查。若包大小超过默认 1.5MB,返回
etcdserver: request is too large错误。
Propose
检查后会生成一个唯一的 ID,将此请求关联到一个对应的消息通知 channel,然后向 Raft 模块 propose 发起一个提案 proposal。
发起 proposal 后,KVServer 会等待写入结果通过消息通知 channel 返回或者超时。默认超时时间是 7 秒(5 秒磁盘 IO 延时+2*1 秒竞选超时时间)。若超时,etcdserver: request timed out 错误。
WAL 模块
Raft 模块收到提案后,如果当前节点是 Follower,它会转发给 Leader。Leader 收到提案后,通过 Raft 模块输出待转发给 Follower 节点的消息和待持久化的日志条目,然后广播给各个节点,同时把集群 Leader 任期号、投票信息、已提交索引、提案内容持久化到一个 WAL(Write Ahead Log)日志文件中,对应流程五。
WAL 日志结构
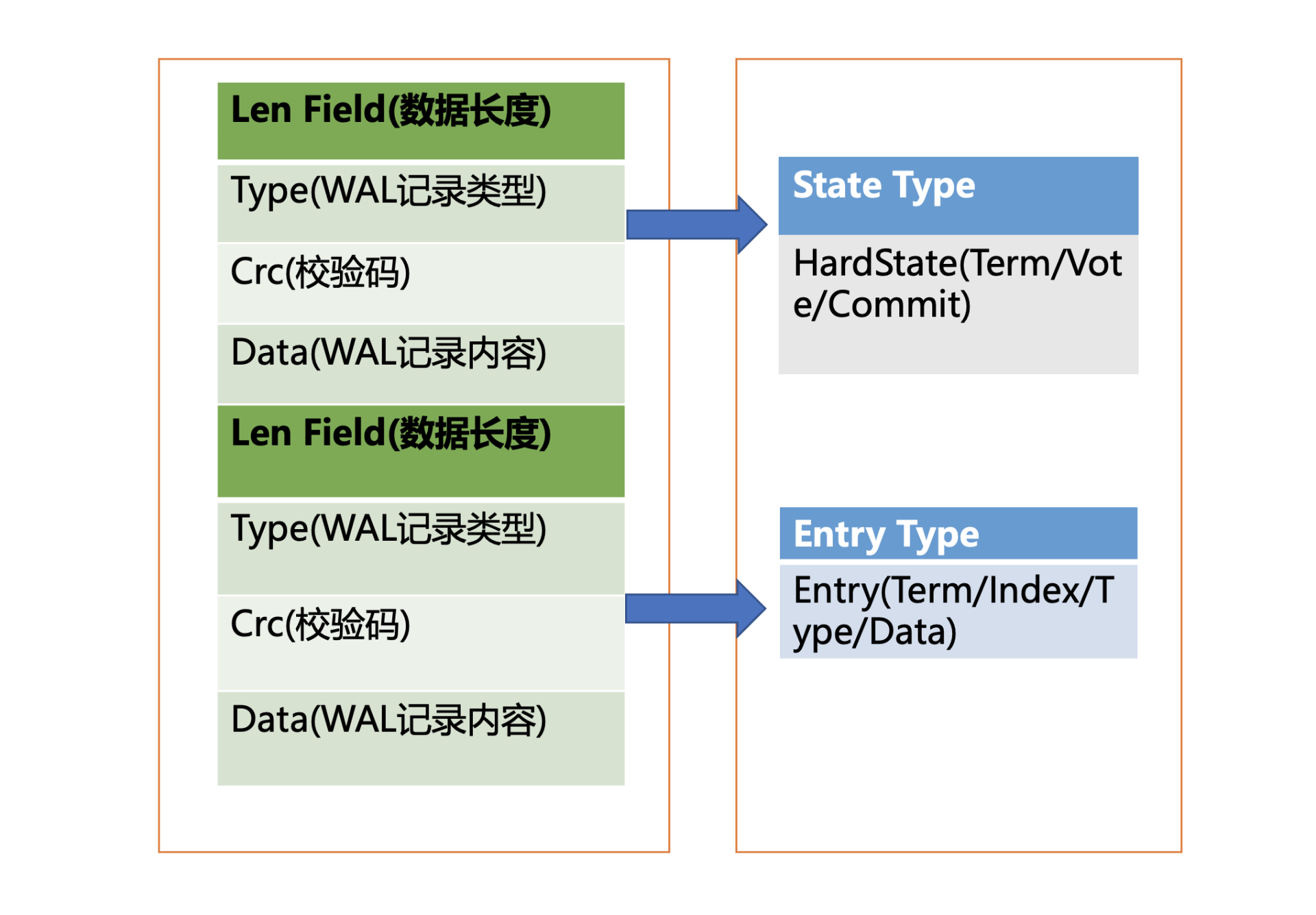
每个记录由类型、数据、循环冗余校验码组成。不同类型的记录通过 Type 字段区分,Data 为对应记录内容,CRC 为循环校验码信息。
WAL 记录类型,目前支持 5 种,分别是文件元数据记录、日志条目记录、状态信息记录、CRC 记录、快照记录。
- 文件元数据记录,包含节点 ID、集群 ID 信息,它在 WAL 文件创建的时候写入;
- 日志条目记录,包含 Raft 日志信息,如 put 提案内容;
- 状态信息记录,包含集群的任期号、节点投票信息等,一个日志文件中会有多条,以最后的记录为准;
- CRC 记录,包含上一个 WAL 文件的最后的 CRC(循环冗余校验码)信息,在创建、切割 WAL 文件时,作为第一条记录写入到新的 WAL 文件,用于校验数据文件的完整性、准确性等;
- 快照记录,包含快照的任期号、日志索引信息,用于检查快照文件的准确性。
Raft 日志条目数据结构
- Term 任期号
- Index 日志索引
- Type 日志类型(命令日志 or 集群配置变更日志)
- Data 提案内容。
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=Raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}WAL 模块保存 Raft 日志条目数据结构方式
首先,Raft 日志条目数据结构,序列化到 WAL 记录中的 Data 字段,计算 CRC 值,设置 Type 为 Entry,组成完整的 WAL 记录。
最后,计算 WAL 记录长度,顺序先写入 WAL 长度,然后写入记录内容,调用 fsync 持久化到磁盘。
当一半以上节点上述持久化后,Raft 模块就会通过 channel 告知 etcdserver 模块,put 提案已经被集群多数节点确认,提案状态为已提交。
Apply 模块
已提交的 Raft 日志条目会进入 FIFO 队列,依次被 Apply 模块执行。
如何保证 Raft 挂了后的正常运行?etcd 重启时,会从 WAL 中解析出 Raft 日志条目内容,追加到 Raft 日志的存储中,并重放已提交的日志提案给 Apply 模块执行。
如何确保幂等性?etcd 引入 consistent index 字段存储系统当前已经执行过的日志条目索引。
Apply 模块在执行提案内容前,首先判断当前提案是否已经执行过了,如果执行了则直接返回,若未执行同时无 db 配额满告警,则进入到 MVCC 模块,开始与持久化存储模块打交道。
Apply 模块除了应用日志条目,还有生成快照 + 应用快照功能。

MVCC 模块
是否需要持久化全局版本号?不需要。启动的时候,从 boltdb 中读取,从最小值 1 开始枚举到最大值,未读到数据的时候则结束,最后读出来的版本号即是当前 etcd 的最大版本号 currentRevision。
写事务流程

boltdb
boltdb 中 key 桶存放需要保存的用户数据,meta 桶存储元数据,例如上面提到的 consistent index 变量。
boltdb 中的 value 包含什么?
- key 名称
- key 创建时的版本号、最后一次修改版本号、自身修改次数
- value 值
- 租约信息
- 将包含上述信息的结构体序列化到 value 中
和 MySQL 一样,put 调用成功,并不代表数据已经持久化到 DB 文件中。事务提交的过程涉及到 B+ 树的平衡和分裂,脏数据、元数据刷新到磁盘等。
为了优化写性能,boltdb 采取“合并”的方式来优化 B+ 树的事务提交过程。
- 调整
bucket.FillPercent参数,使得每个 page 可以填充更多数据,减少分裂次数 - 合并多个写事务请求,异步定时(默认 100ms)批量将事务一次性提交,除非 pending 事务过多才触发同步提交。
同样,由于事务未提交时,DB 文件并非最新数据,所以更新 boltdb 时候,数据也会同步到 buffer 中。对应读请求时候先从 buffer 中读数据,没有再访问 DB 文件。
boltdb 的压缩模块支持按多种方式回收旧版本,比如保留最近一段时间内的历史版本。但仅仅只是将占用的空间打上 Free 标记,后续数据可以复用这块空间,无需申请新空间。这个好像和 MySQL、Redis 一样处理,Redis 删除的时候内存好像并不归还,MySQL 也是。
如果需要回收空间,减少 db 文件大小,需要执行碎片整理。但这就会增加 CPU 的开销,不适合在生产环境下轻易使用。
list pod 是否影响写请求性能
回顾下 etcd 读写性能优化历史。
在 etcd 3.0 中,线性读请求需要走一遍 Raft 协议持久化到 WAL 日志中,因此读性能非常差,写请求肯定也会被影响。
在 etcd 3.1 中,引入了 ReadIndex 机制提升读性能,读请求无需再持久化到 WAL 中。
在 etcd 3.2 中, 优化思路转移到了 MVCC/boltdb 模块,boltdb 的事务锁由粗粒度的互斥锁,优化成读写锁,实现“N reads or 1 write”的并行,同时引入了 buffer 来提升吞吐量。问题就出在这个 buffer,读事务会加读锁,写事务结束时要升级锁更新 buffer,但是 expensive request 导致读事务长时间持有锁,最终导致写请求超时。
在 etcd 3.4 中,实现了全并发读,创建读事务的时候会全量拷贝 buffer, 读写事务不再因为 buffer 阻塞,大大缓解了 expensive request 对 etcd 性能的影响。尤其是 Kubernetes List Pod 等资源场景来说,etcd 稳定性显著提升。