生产者分区策略:
- 轮询策略,2.4 前默认策略。
- 随机策略。
- 按消息键保序策略。基于 key 进行 hash 后分到各个区。
- 粘性分区策略,2.4 后默认策略。
- 地理位置分区。
- 直接指定分区
- …
消费者分区分配策略:
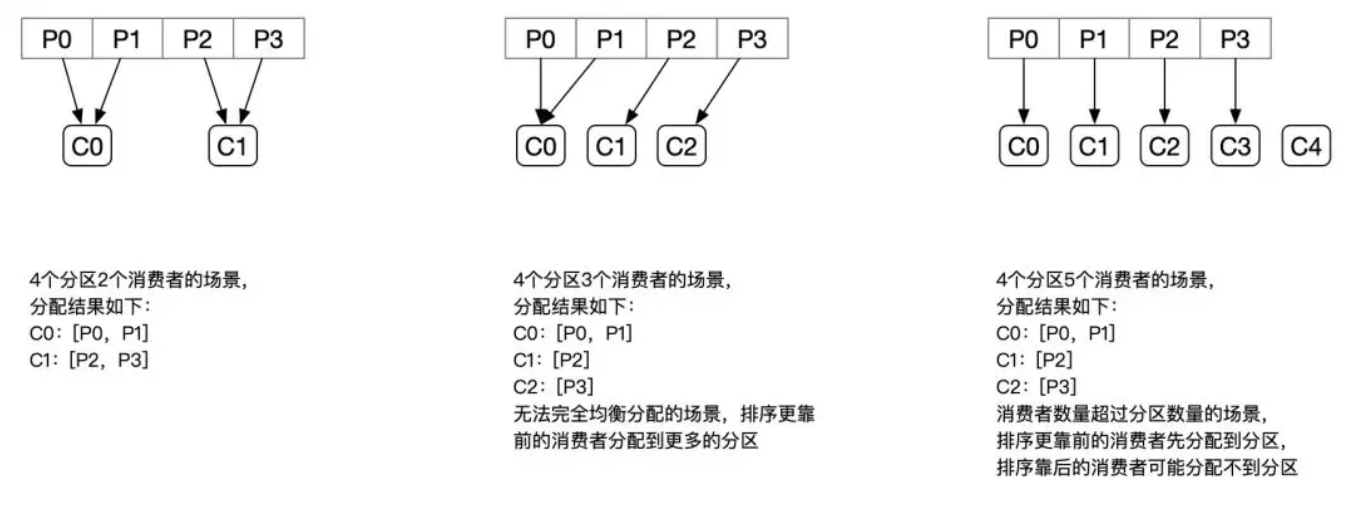
- RangeAssigor(范围):同一个 Topic 尽可能平均,但是多 Topic 下差距越来越大。
- RoundRobinAssignor(轮询):同一个 ConsumerGroup 尽可能平均,但如果订阅的 Topic 列表是不同的,那么分配结果是不保证“尽量均衡”的,因为某些消费者不参与一些 Topic 的分配。。
- StickyAssignor(粘性):尽可能均衡,且尽可能少移动分区。
生产者分区策略
有哪些分区策略?
如果要自定义分区策略,你需要显式地配置生产者端的参数 partitioner.class。这个参数该怎么设定呢?方法很简单,在编写生产者程序时,你可以编写一个具体的类实现 org.apache.kafka.clients.producer.Partitioner 接口。这个接口也很简单,只定义了两个方法:partition() 和 close(),通常你只需要实现最重要的 partition 方法。我们来看看这个方法的方法签名:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);这里的 topic、key、keyBytes、value 和 valueBytes 都属于消息数据,cluster 则是集群信息(比如当前 Kafka 集群共有多少主题、多少 Broker 等)。Kafka 给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。只要你自己的实现类定义好了 partition 方法,同时设置 partitioner.class 参数为你自己实现类的 Full Qualified Name,那么生产者程序就会按照你的代码逻辑对消息进行分区。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一,也是 Kafka 在没有 key 时的默认分区策略。
随机策略就是我们随意地将消息放置到任意一个分区上,但是没办法保证数据是均匀分布的,一般不会采用。具体使用待如下:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());按消息键保序策略是指对 key 值进行处理,比如 hash,使得同分区的 key 有一定意义。Kafka 在存在 key 时的默认分区策略。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();地理位置分区策略,假如针对不同地区有不同的消息,可以考虑这种。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return partitions.stream().filter(p -> isSouth(p.leader().host())).map(PartitionInfo::partition).findAny().get();粘性分区策略进行分区。2.4 后新的分区策略。
- 如果指定分区,就直接使用该分区。
- 未指定分区但存在 key,则根据序列化 key 使用 murmur2 哈希算法对分区数取模
- 如果不存在分区或 key,则会使用粘性分区策略。
分区策略并不是固定的,需要根据实际情况自定义来更好的提高性能。
消息重试只是简单地将消息重新发送到之前的分区。
看似只能全局顺序的消息,也是可能存在 key+多分区的实现方式,需要将因果联系分析清楚。
kafka-topics 支持在创建 topic 时指定 partition 放在那些 broker 上
粘性分区策略详解
为什么会有粘性分区的概念?
首先,我们指定,Producer 在发送消息的时候,会将消息放到一个 ProducerBatch 中, 这个 Batch 可能包含多条消息,然后再将 Batch 打包发送。
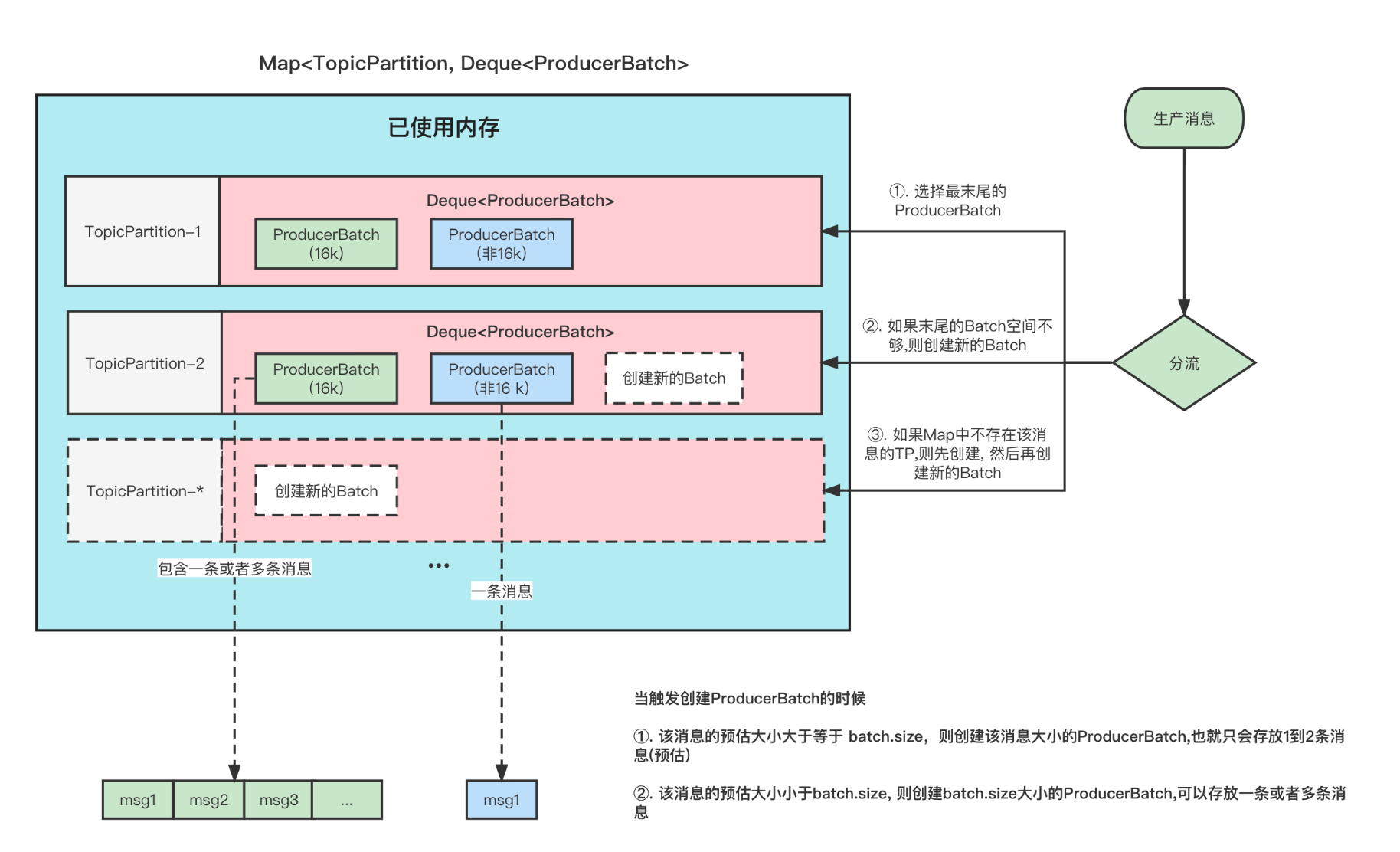
这样做的好处就是能够提高吞吐量,减少发起请求的次数。
但是有一个问题就是, 因为消息的发送它必须要你的一个 Batch 满了或者 linger.ms 时间到了,才会发送。如果生产的消息比较少的话,迟迟难以让 Batch 塞满,那么就意味着更高的延迟。
在之前的消息发送中,就将消息轮询到各个分区的, 本来消息就少,你还给所有分区遍历的分配,那么每个 ProducerBatch 都很难满足条件。
这张图的前提是:
Topic1 有 3 分区, 此时给 Topic1 发 9 条无 key 的消息, 这 9 条消息加起来都不超过 batch.size .
那么以前的分配方式和粘性分区的分配方式如下
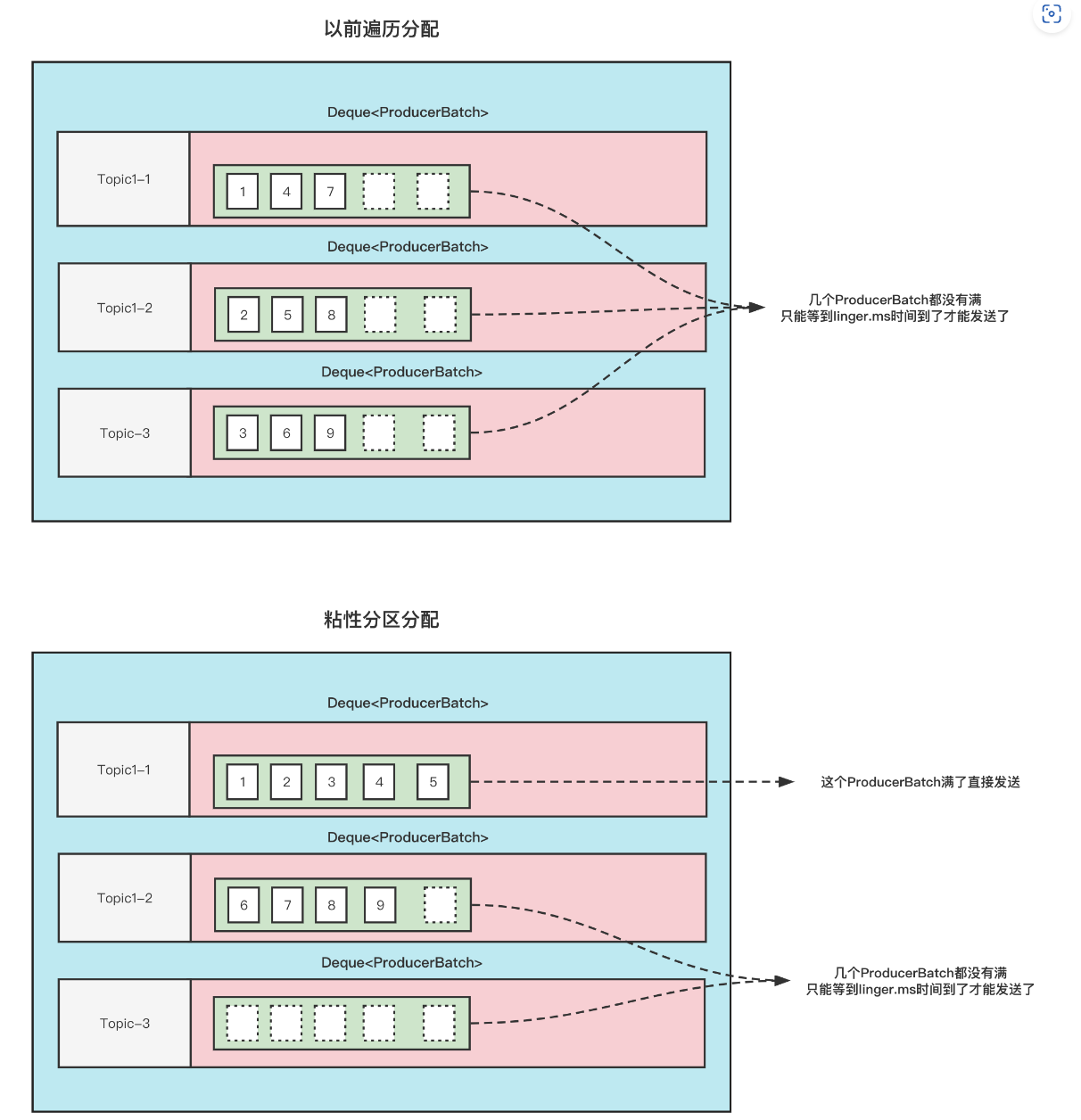
可以看到,使用粘性分区之后,至少是先把一个 Batch 填满了发送然后再去填充另一个 Batch。不至于向之前那样,虽然平均分配了,但是导致一个 Batch 都没有放满,不能立即发送。这不就增大了延迟了吗(只能通过 linger.ms 时间到了才发送)
划重点:
-
当一个 Batch 发送之后,需要选择一个新的粘性分区的时候
- 可用分区<1 ;那么选择分区的逻辑是在所有分区中随机选择。
- 可用分区=1;那么直接选择这个分区。
- 可用分区>1 ; 那么在所有可用分区中随机选择。
-
当选择下一个粘性分区的时候,不是按照分区平均的原则来分配。而是随机原则(当然不能跟上一次的分区相同)
例如刚刚发送到的 Batch 是 1 号分区,等 Batch 满了,发送之后,新的消息可能会发到 2 或者 3, 如果选择的是 2,等 2 的 Batch 满了之后,下一次选择的 Batch 仍旧可能是 1,而不是说为了平均,选择 3 分区。
增加数据后,会根据当前粘性分区中生产的数据量进行判断,是不是需要切换其他的分区。判断标准就是大于等于批次大小(16K)的 2 倍,或大于一个批次大小 (16K)且需要切换。如果满足条件,下一条数据就会放置到其他分区。
Python & Go 显示指定分区
kafka-python 可以支持
producer.send(topic, b'some_message_bytes', partiion=1)kafka-go 需要实现对应接口达到类似效果
type CustomBalancer struct {
kfk.RoundRobin
}
//nolint
func (h *CustomBalancer) Balance(msg kfk.Message, partitions ...int) int {
if msg.Partition == -1 {
return h.RoundRobin.Balance(msg, partitions...)
}
return msg.Partition
}消费者可以显式指定消费分区,消费者组通过自平衡分配分区。
Java 自定义分区
Java 自定义分区器就是实现 Partitioner 接口。
public class KafkaPartitionerMock implements Partitioner {
/**
* 分区算法 - 根据业务自行定义即可
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes The serialized key to partition on( or null if no key)
* @param value The value to partition on or null
* @param valueBytes The serialized value to partition on or null
* @param cluster The current cluster metadata
* @return 分区编号,从 0 开始
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}消费分区分配策略
Kafka 中提供了多重分区分配算法(PartitionAssignor)的实现:RangeAssigor、RoundRobinAssignor、StickyAssignor。本文主要介绍 StickyAssignor,顺带会介绍 RangeAssigor、RoundRobinAssignor 作为分区分配的背景知识。
RangeAssignor
PartitionAssignor 接口用于用户定义实现分区分配算法,以实现 Consumer 之间的分区分配。消费组的成员订阅它们感兴趣的 Topic 并将这种订阅关系传递给作为订阅组协调者的 Broker。协调者选择其中的一个消费者来执行这个消费组的分区分配并将分配结果转发给消费组内所有的消费者。Kafka 默认采用 RangeAssignor 的分配算法。
RangeAssignor 对每个 Topic 进行独立的分区分配。对于每一个 Topic,首先对分区按照分区 ID 进行排序,然后订阅这个 Topic 的消费组的消费者再进行排序,之后尽量均衡的将分区分配给消费者。这里只能是尽量均衡,因为分区数可能无法被消费者数量整除,那么有一些消费者就会多分配到一些分区。
分配示意图如下:
RangeAssignor 策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个 Topic,RangeAssignor 策略会将消费组内所有订阅这个 Topic 的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
这种分配方式明显的一个问题是随着消费者订阅的 Topic 的数量的增加,不均衡的问题会越来越严重,比如上图中 4 个分区 3 个消费者的场景,C0 会多分配一个分区。如果此时再订阅一个分区数为 4 的 Topic,那么 C0 又会比 C1、C2 多分配一个分区,这样 C0 总共就比 C1、C2 多分配两个分区了,而且随着 Topic 的增加,这个情况会越来越严重。
分配结果:
订阅 2 个 Topic,每个 Topic4 个分区,共 3 个 Consumer
C0:[T0P0,T0P1,T1P0,T1P1]C1:[T0P2,T1P2]C2:[T0P3,T1P3]
RoundRobinAssignor
RoundRobinAssignor 的分配策略是将消费组内订阅的所有 Topic 的分区及所有消费者进行排序后尽量均衡的分配(RangeAssignor 是针对单个 Topic 的分区进行排序分配的)。如果消费组内,消费者订阅的 Topic 列表是相同的(每个消费者都订阅了相同的 Topic),那么分配结果是尽量均衡的(消费者之间分配到的分区数的差值不会超过 1)。如果订阅的 Topic 列表是不同的,那么分配结果是不保证“尽量均衡”的,因为某些消费者不参与一些 Topic 的分配。
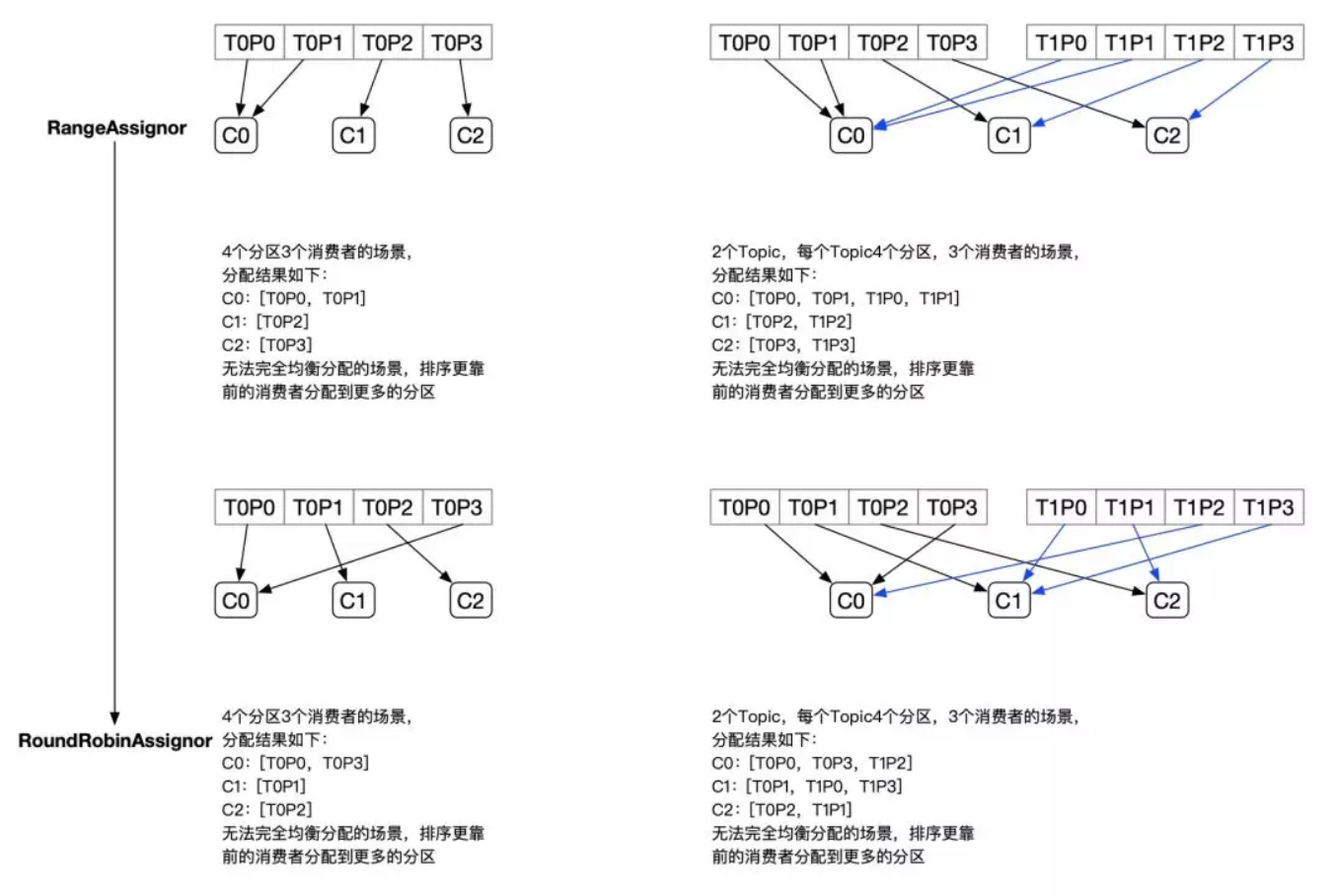
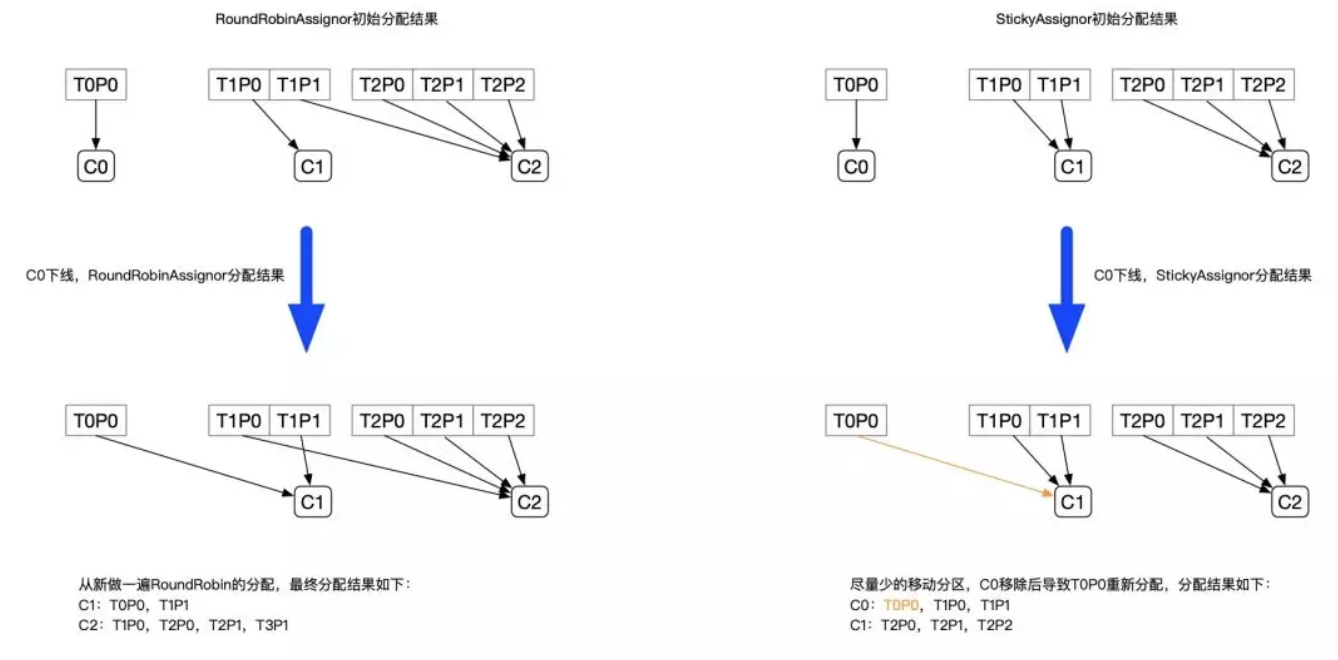
但是可能不均衡的情况:
StickyAssignor
动机
尽管 RoundRobinAssignor 已经在 RangeAssignor 上做了一些优化来更均衡的分配分区,但是在一些情况下依旧会产生严重的分配偏差,比如消费组中订阅的 Topic 列表不相同的情况下(这个情况可能更多的发生在发布阶段,但是这真的是一个问题吗?——可以参照 Kafka 官方的说明:KIP-49 Fair Partition Assignment Strategy)。更核心的问题是无论是 RangeAssignor,还是 RoundRobinAssignor,当前的分区分配算法都没有考虑上一次的分配结果。显然,在执行一次新的分配之前,如果能考虑到上一次分配的结果,尽量少的调整分区分配的变动,显然是能节省很多开销的。
目标
从字面意义上看,Sticky 是“粘性的”,可以理解为分配结果是带“粘性的”——每一次分配变更相对上一次分配做最少的变动(上一次的结果是有粘性的),其目标有两点:
1. 分区的分配尽量的均衡
2. 每一次重分配的结果尽量与上一次分配结果保持一致
当这两个目标发生冲突时,优先保证第一个目标。第一个目标是每个分配算法都尽量尝试去完成的,而第二个目标才真正体现出 StickyAssignor 特性的。
我们先来看预期分配的结构,后续再具体分析 StickyAssignor 的算法实现。
例如:
- 有 3 个 Consumer:C0、C1、C2
- 有 4 个 Topic:T0、T1、T2、T3,每个 Topic 有 2 个分区
- 所有 Consumer 都订阅了这 4 个分区
StickyAssignor 的分配结果如下图所示(增加 RoundRobinAssignor 分配作为对比):
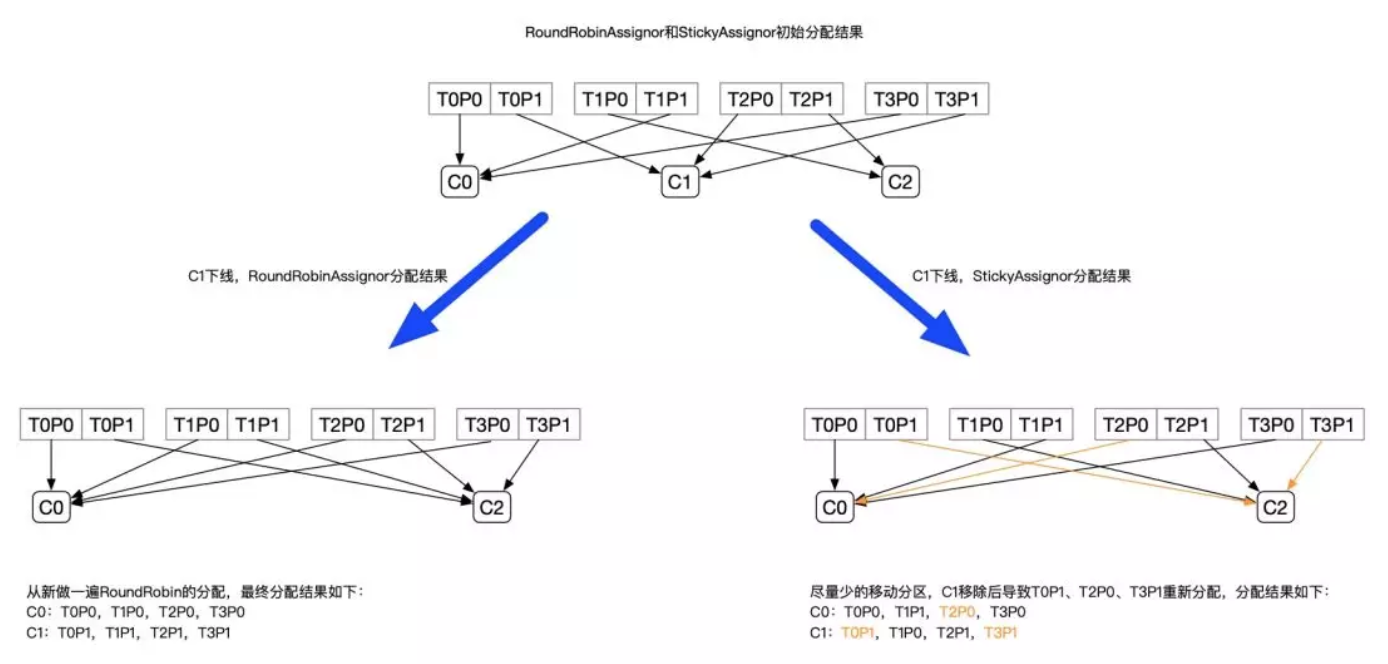

上面的例子中,Sticky 模式原来分配给 C0、C2 的分区都没有发生变动,且最终 C0、C1 达到的均衡的目的。
再举一个例子:
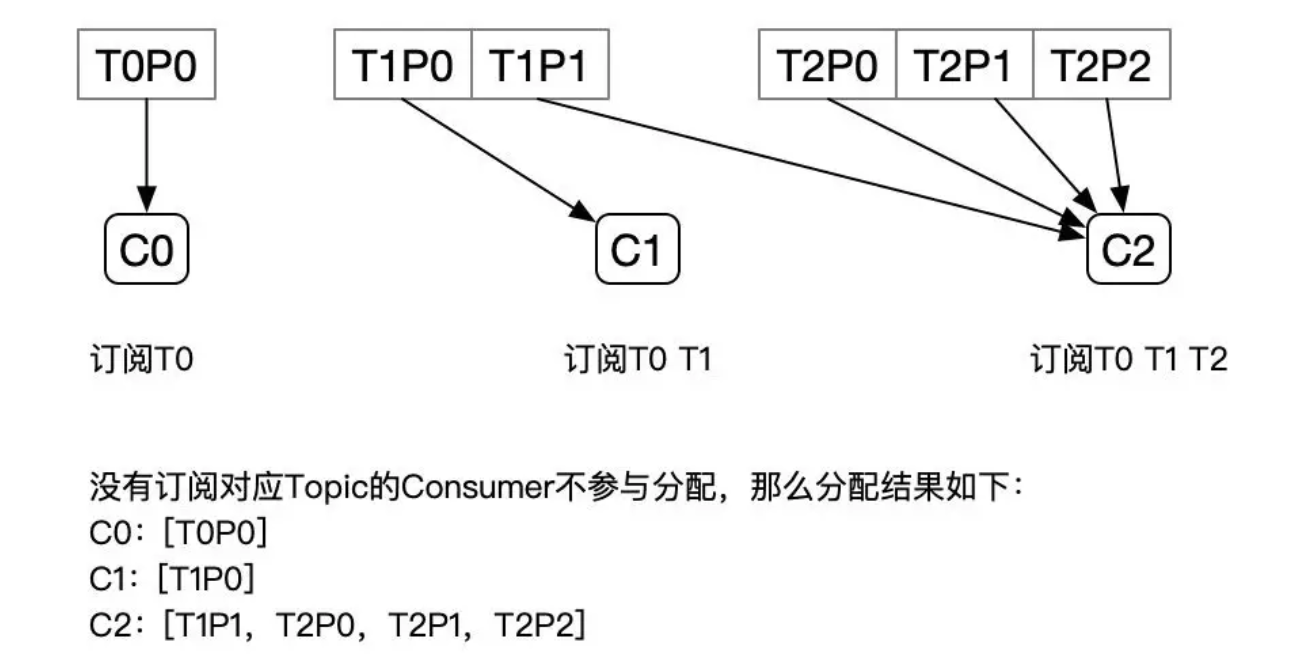
- 有 3 个 Consumer:C0、C1、C2
- 3 个 Topic:T0、T1、T2,它们分别有 1、2、3 个分区
- C0 订阅 T0;C1 订阅 T0、T1;C2 订阅 T0、T1、T2
分配结果如下图所示:
从以上两个例子的分配结果可以看出,StickyAssignor 是比 RangeAssignor 和 RoundRobinAssignor 更好的分配方式,不过它的实现也更加的复杂。