1 多线程开发消费者
从 Kafka 0.10.1.0 版本开始,KafkaConsumer 就变为了双线程的设计,即用户主线程和心跳线程。
现在呢? TODO
KafkaConsumer 类不是线程安全的 (thread-safe)。所有的网络 I/O 处理都是发生在用户主线程中,因此,你在使用过程中必须要确保线程安全。简单来说,就是你不能在多个线程中共享同一个 KafkaConsumer 实例,否则程序会抛出 ConcurrentModificationException 异常。
当然了,这也不是绝对的。KafkaConsumer 中有个方法是例外的,它就是 wakeup(),你可以在其他线程中安全地调用 KafkaConsumer.wakeup() 来唤醒 Consumer。
现在呢? TODO
多线程下的设计:
方法一,线程数 = 分区数,每个线程创建独立 Consumer 去消费。
方法二,n>=1 线程获取 m 个分区的消息,每个线程创建独立 Consumer 去消费,再由多个线程(线程池)去消费消息。
方法一的优点:(1) 方便实现 (2) 速度快,无线程间交互开销 (3) 易于维护 partition 内消费顺序
方法一的缺点:(1) 占用更多资源 (2) 线程数受限于分区数,扩展差 (3) 若线程自己处理消息容易超时,从而引发 Rebalance。
方法二的优点:(1) 获取消息的线程与消费消息的线程数目独立 (2) 伸缩性好
方法二的缺点:(1) 实现困难 (2) 难以维护 partition 内消费顺序 (3) 处理链路拉长,不易 offset 提交管理。
关于方案二的实现,有兴趣的话可以阅读以下 Flink 中 Kafka Connector 的源代码。
2 | 消费者组消费进度监控都怎么实现?
对于 Kafka 消费者来说,最重要的事情就是监控它们的消费进度了,或者说是监控它们消费的滞后程度。这个滞后程度有个专门的名称:消费者 Lag 或 Consumer Lag。
一个正常工作的消费者,它的 Lag 值应该很小,甚至是接近于 0 的,如果一个消费者 Lag 值很大,通常就表明它无法跟上生产者的速度,最终 Lag 会越来越大,从而拖慢下游消息的处理速度。
想到了之前字节实习的时候,看到的 Kafka Grafana 面板。当时小说场景的离线数据开始灌入后,Kafka 的 Lag 会逐步增加,再某个时间点后又慢慢降低到 0.
有三种方式实现 Lag 监控:
- 使用 Kafka 自带的命令行工具 kafka-consumer-groups 脚本。
- 使用 Kafka Java Consumer API 编程。
- 使用 Kafka 自带的 JMX 监控指标。
2.1 Kafka 自带的命令行工具
bin/kafka-consumer-groups.sh --bootstrap-server host:ip --describe --group group.idTODO 看一下当前线上环境的 Kafka Lag,应该是 0
运行命令时,如果提示 “Consumer group xxx has no active members” 代表当前没有 active 消费者消费。
2.2 Kafka Java Consumer API
// 获取当前的偏移量
Map<TopicPartition, OffsetAndMetadata> currentOffsets = consumer.position(consumer.assignment());
// 获取最新的偏移量
Map<TopicPartition, Long> endOffsets = consumer.endOffsets(consumer.assignment());
// 计算 Lag
for (TopicPartition tp : currentOffsets.keySet()) {
long currentOffset = currentOffsets.get(tp).offset();
long endOffset = endOffsets.get(tp);
long lag = endOffset - currentOffset;
System.out.println("Lag for partition " + tp + ": " + lag);
}2.3 Kafka JMX 监控指标
Kafka 消费者提供了一个名为 kafka.consumer:type=consumer-fetch-manager-metrics,client-id=“{client-id}” 的 JMX 指标,里面包含了 records-lag-max 和 records-lead-min 分别表示此消费者在测试窗口时间内曾经达到的最大的 Lag 值和最小的 Lead 值。其中,Lead 值是指消费者最新消费消息的位移与分区当前第一条消息位移的差值。
需要注意的是,若 Lead 越来越小,甚至是快接近于 0 了,有可能会丢失数据。Kafka 的消息是有留存时间设置的,默认是 1 周,也就是说 Kafka 默认删除 1 周前的数据。
Kafka 消费者还在分区级别提供了额外的 JMX 指标,用于单独监控分区级别的 Lag 和 Lead 值。JMX 名称为:kafka.consumer:type=consumer-fetch-manager-metrics,partition=“{partition}”,topic=“{topic}”,client-id=“{client-id}”。
真实业务场景中,我们采用过 kafka tool,kafka manager 和 jconsole 和 jvisualvm。如果监控 kafka 主题、分区、数据流入流出、调整分区数、Lag 等 kafka manager 比较直观好看,不推荐 kafka tool,不方便会卡顿。如果要监控内存、线程安全、进程,Lag、Lead 等的话,就会使用 jconsole 和 jvisualvm,另外,有利于排查 kafka 是否存在死锁问题。
3 | Kafka 副本机制详解
3.1 副本概念
所谓副本(Replica),本质就是一个只能追加写消息的提交日志。根据 Kafka 副本机制的定义,同一个分区下的所有副本保存有相同的消息序列,这些副本分散保存在不同的 Broker 上,从而能够对抗部分 Broker 宕机带来的数据不可用。
在实际生产环境中,每台 Broker 都可能保存有各个主题下不同分区的不同副本,因此,单个 Broker 上存有成百上千个副本的现象是非常正常的。
3.2 如何确保数据一致性问题
最常见的解决方案就是采用基于领导者(Leader-based)的副本机制。Apache Kafka 就是这样的设计。
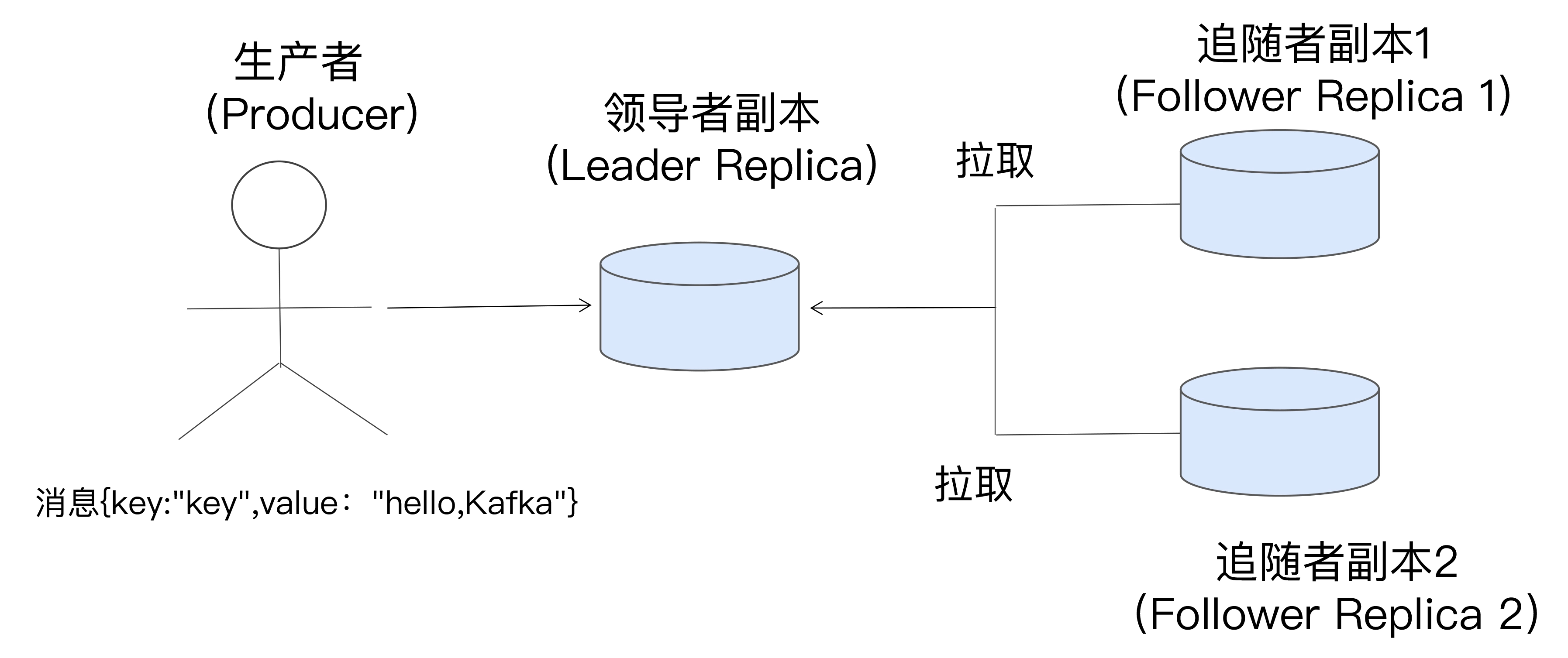
第一,副本分成两类:一个领导者副本 Leader Replica,其他是追随者副本 Follower Replica。
第二,追随者副本是不对外提供服务的。它唯一的任务就是从领导者副本异步拉取消息,并写入到自己的提交日志中,从而实现与领导者副本的同步。
第三,当领导者副本挂掉了,或者说领导者副本所在的 Broker 宕机时,Kafka 依托于 ZooKeeper 提供的监控功能能够实时感知到,并立即开启新一轮的领导者选举,从追随者副本中选一个作为新的领导者。老 Leader 副本重启回来后,只能作为追随者副本加入到集群中。
注意上面的第二点,即追随者副本是不对外提供服务的。所以,Kafka 不能通过副本来实现横向扩展。
设计这种副本的好处:(1) 立刻消费,避免副本拉取延迟。(2)避免不同副本之间数据不一致,导致一会存在一会消失,
感觉这个可以通过一致性来解决啊。要求副本都收到消息再 ack,保证不会出现 (2) 情况。
3.3 In-sync Replicas(ISR)
Kafka 引入了 In-sync Replicas,也就是所谓的 ISR 副本集合。ISR 中的副本都是与 Leader 同步的副本,相反,不在 ISR 中的追随者副本就被认为是与 Leader 不同步的。
ISR 是动态变更的,判断副本能否存留在 ISR 中是根据 Broker 端参数 replica.lag.time.max.ms 参数值确定。Kafka在启动的时候会开启两个任务,一个任务用来定期地检查是否需要缩减或者扩大ISR集合,这个周期是 replica.lag.time.max.ms 的一半,默认 5000ms。若某个 Follower 副本能够落后 Leader 副本超过 replica.lag.time.max.ms ,那么就认为是失效副本,就会收缩 ISR。当检查到有 Follower 的 HighWatermark 追赶上 Leader 时,就会扩充 ISR。
除此之外,当 ISR 集合发生变更的时候还会将变更后的记录缓存到 isrChangeSet 中,另外一个任务会周期性地检查这个 Set,如果发现这个 Set 中有 ISR 集合的变更记录,那么它会在 zk 中持久化一个节点。然后因为 Controllr 在这个节点的路径上注册了一个 Watcher,所以它就能够感知到 ISR 的变化,并向它所管理的 broker 发送更新元数据的请求。最后删除该路径下已经处理过的节点。
3.4 Unclean 领导者选举(Unclean Leader Election)
Kafka 把所有不在 ISR 中的存活副本都称为非同步副本。通常来说,这些副本落后 Leader 太多。
若 ISR 中一个副本都不存在,那么意味着包括 Leader 的所有副本都挂掉了,那么 Kafka 就必须要选择一个 Leader,选举这种副本的过程称为 Unclean Leader Election。Broker 端参数 unclean.leader.election.enable 控制是否允许 Unclean 领导者选举。
Unclean Leader Election 可能会造成数据丢失,但好处是,它使得分区 Leader 副本一直存在,不至于停止对外提供服务,因此提升了高可用性。反之,禁止 Unclean 领导者选举的好处在于维护了数据的一致性,避免了消息丢失,但牺牲了高可用性。
CAP 理论中一致性 Consistency、可用性 Availability、分区容错性 Partition tolerance,Kafka 在此时赋予了选择一致性和可用性。
根据实际业务判断是否需要开启 Unclean Leader Election。专栏作家强烈不推荐开启,可以通过其他方式来提高可用性。不必要为了这点高可用改善牺牲了数据一致性。
增加副本数是其中一个解决办法。Producer 设置 ack=all + 最小 ISR,从而避免出现这种情况。
4 | 请求是怎么被处理的?
4.1 Kafka 是如何处理请求的?
谈到 Reactor 模式,大神 Doug Lea 的“Scalable IO in Java”应该算是最好的入门教材了。整个 java.util.concurrent 包都是他的杰作。
Reactor 模式是事件驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发送请求的场景。
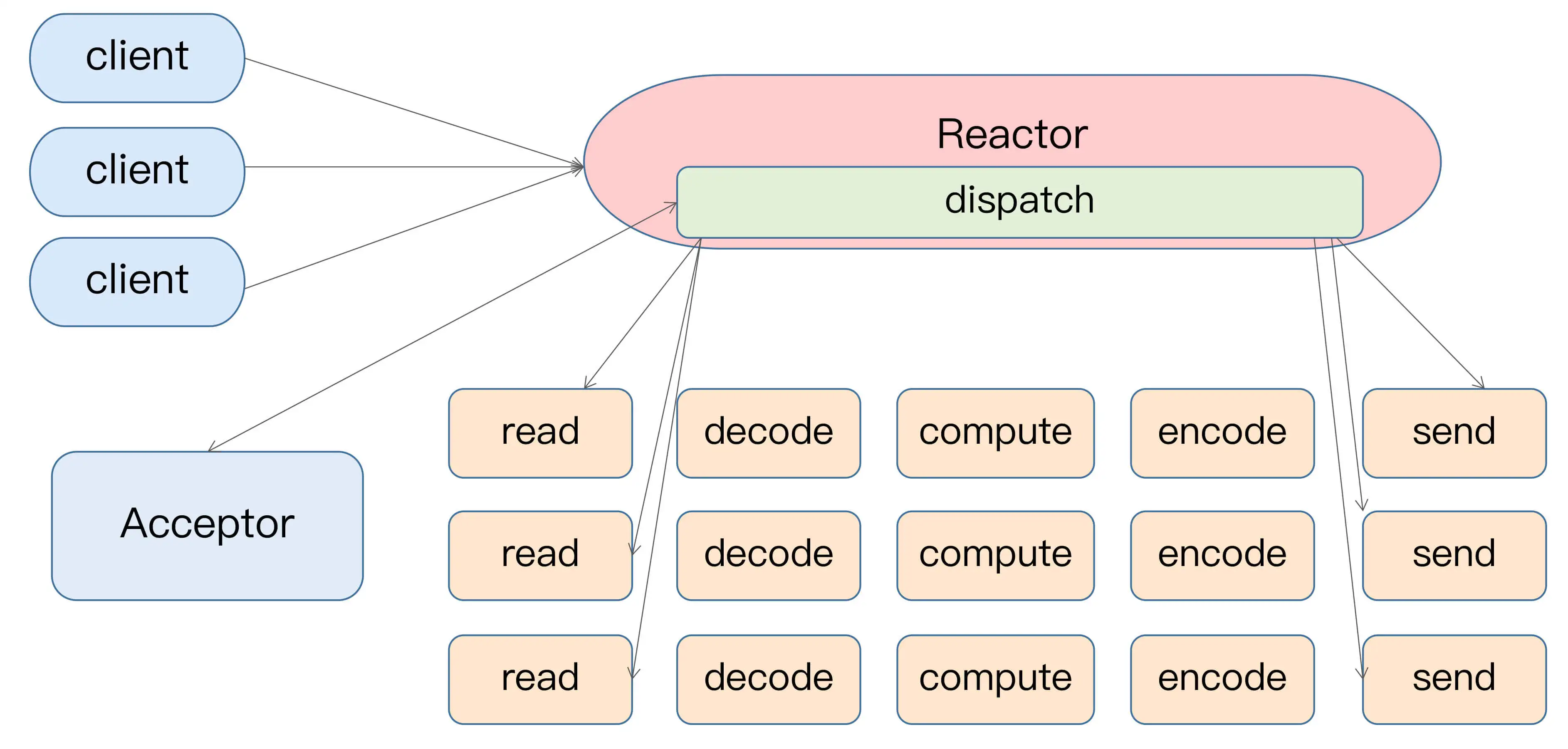
从这张图中,我们可以发现,多个客户端会发送请求给到 Reactor。Reactor 有个请求分发线程 Dispatcher,也就是图中的 Acceptor,它会将不同的请求下发到多个工作线程中处理。
在这个架构中,Acceptor 线程只是用于请求分发,不涉及具体的逻辑处理,非常得轻量级,因此有很高的吞吐量表现。而这些工作线程可以根据实际业务处理需要任意增减,从而动态调节系统负载能力。
如果我们来为 Kafka 画一张类似的图的话,那它应该是这个样子的:
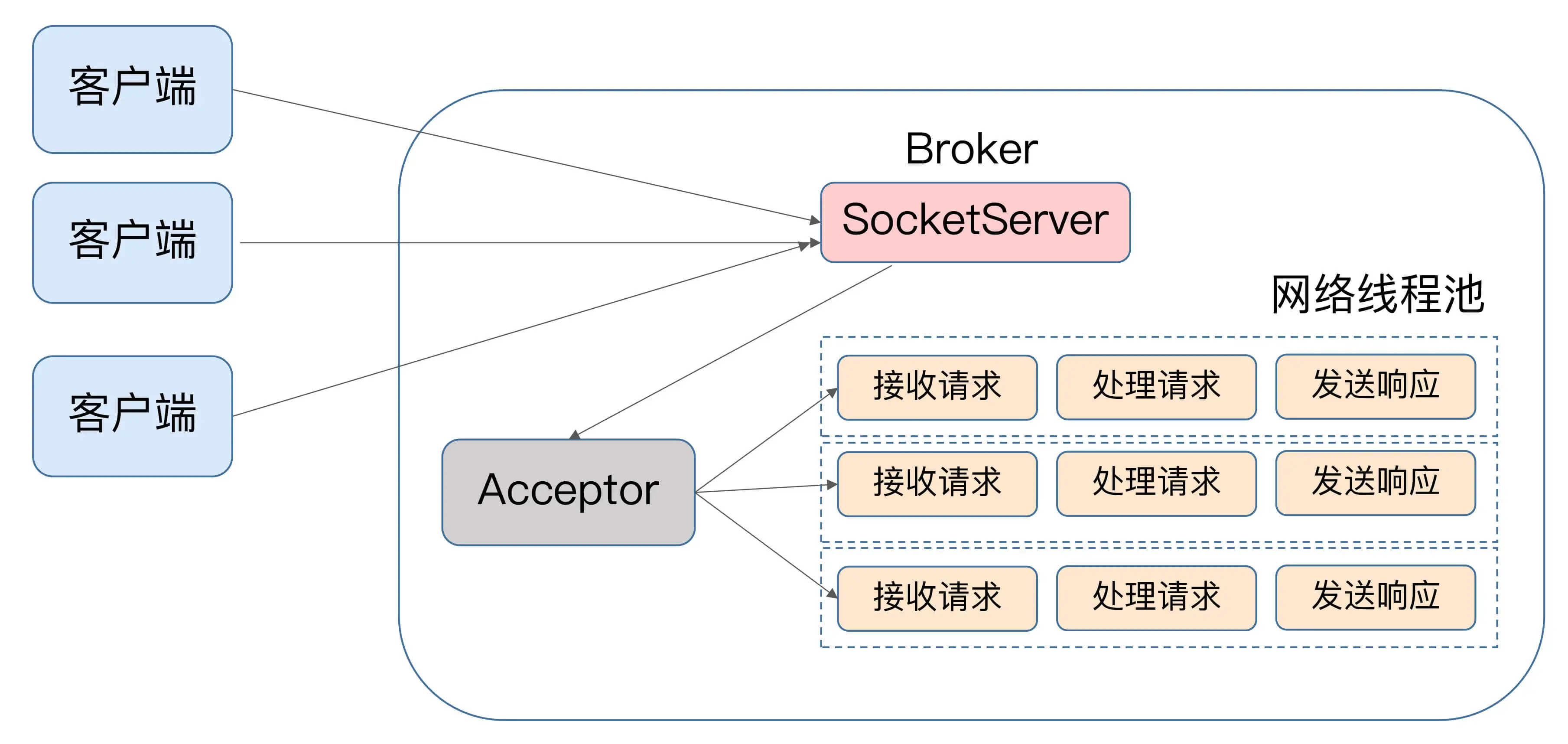
Kafka 的线程池有个专门的名字,网络线程池。Kafka 提供了 Broker 端参数 num.network.threads,用于调整该网络线程池的线程数。其默认值是 3,表示每台 Broker 启动时会创建 3 个网络线程,专门处理客户端发送的请求。Acceptor 线程采用轮询的方式将入站请求公平地发到所有网络线程中。
网络线程池在接收到请求后的处理逻辑大概是:
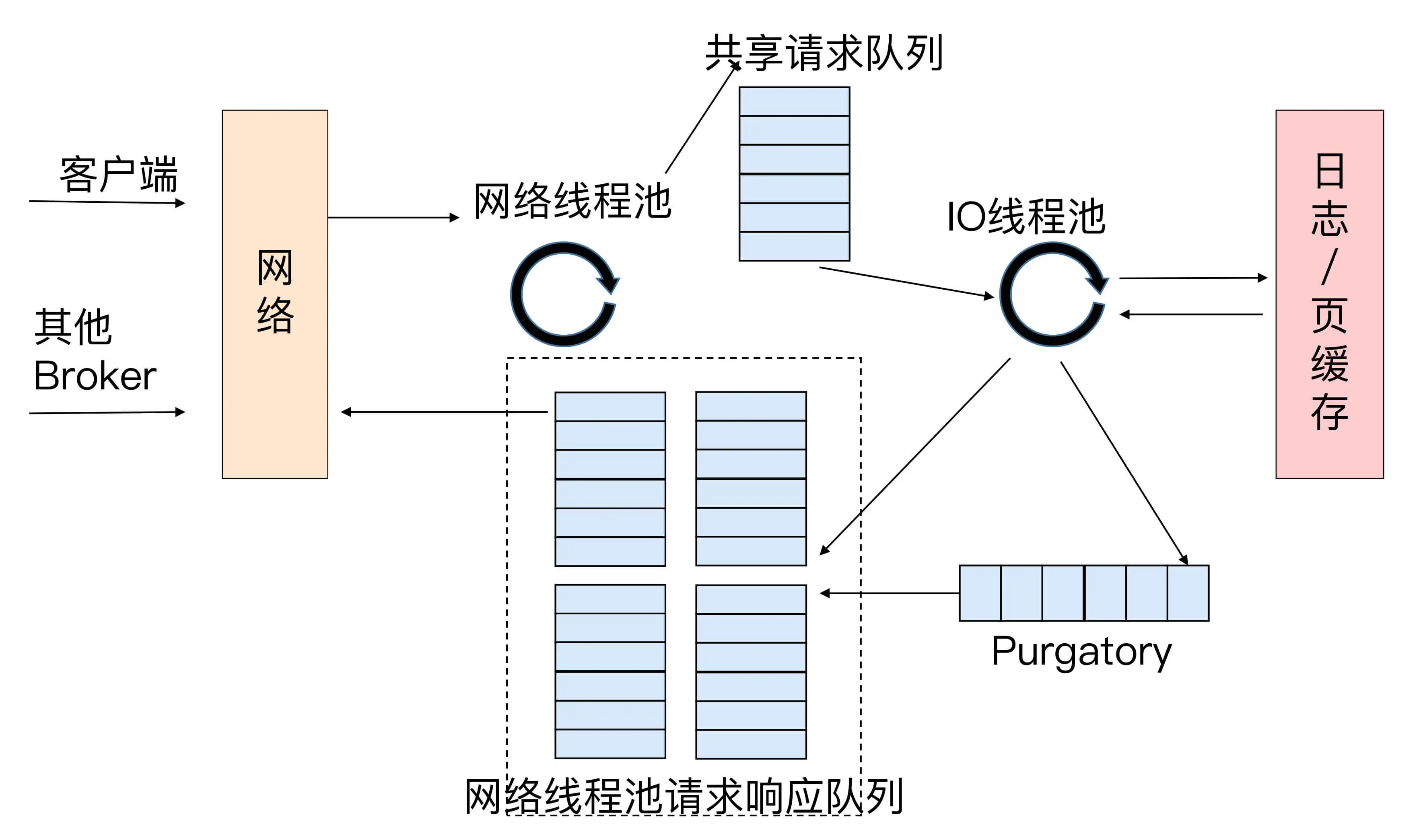
当网络线程拿到请求后,它不是自己处理,而是将请求放入到一个共享请求队列中。Broker 端还有个 IO 线程池,负责从该队列中取出请求,执行真正的处理。如果是 PRODUCE 生产请求,则将消息写入到底层的磁盘日志中;如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
IO 线程池处中的线程才是执行请求逻辑的线程。Broker 端参数 num.io.threads 控制了这个线程池中的线程数。目前该参数默认值是 8,表示每台 Broker 启动后自动创建 8 个 IO 线程处理请求。你可以根据实际硬件条件设置此线程池的个数。
比如,如果你的机器上 CPU 资源非常充裕,你完全可以调大该参数,允许更多的并发请求被同时处理。当 IO 线程处理完请求后,会将生成的响应发送到网络线程池的响应队列中,然后由对应的网络线程负责将 Response 返还给客户端。
细心的你一定发现了请求队列和响应队列的差别:请求队列是所有网络线程共享的,而响应队列则是每个网络线程专属的。这么设计的原因就在于,Dispatcher 只是用于请求分发而不负责响应回传,因此只能让每个网络线程自己发送 Response 给客户端,所以这些 Response 也就没必要放在一个公共的地方。
图中有一个叫 Purgatory 的组件,这是 Kafka 中著名的“炼狱”组件。它是用来缓存延时请求(Delayed Request)的。所谓延时请求,就是那些一时未满足条件不能立刻处理的请求。比如设置了 acks=all 的 PRODUCE 请求,一旦设置了 acks=all,那么该请求就必须等待 ISR 中所有副本都接收了消息后才能返回,此时处理该请求的 IO 线程就必须等待其他 Broker 的写入结果。当请求不能立刻处理时,它就会暂存在 Purgatory 中。稍后一旦满足了完成条件,IO 线程会继续处理该请求,并将 Response 放入对应网络线程的响应队列中。
4.2 控制类请求和数据类请求分离
TODO。