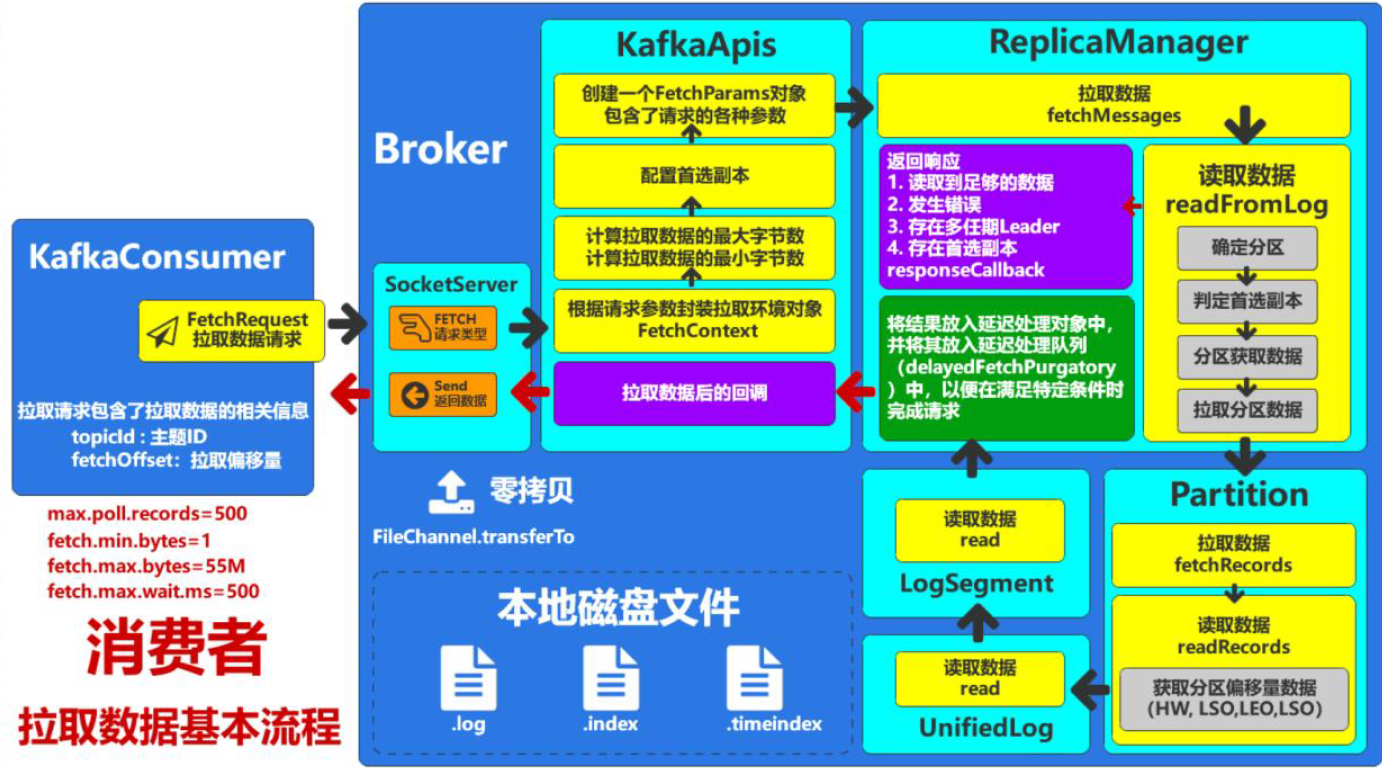
消费消息时的基本步骤
配置 Consumer 属性
Java Kafka Consumer 需要配置的属性信息
- boostrap.servers: 集群地址
- key.deserializer
- value.deservializer
- group.id: 消费组 ID
- auto.offset.reset
- group.instance.id: 消费者实例 ID,如果指定,那么在消费者组中使用此 ID 作为 memberId 前缀
- partition.assignment.strategy: 分区分配策略
- enable.auto.commit: 默认 true
- auto.commit.interval.ms: 默认 5000ms
- fetch.max.bytes: 消费者获取服务器端一批消息最大的字节数。如果服务端一批次的数据大于该值,仍然可以拉去回来这批数据。即不是一个绝对最大值,受到 message.max.bytes (broker config) or max.message.bytes (topic) 影响。默认值 50m。
- offset.topic.num.partitions: 偏移量消费主题分区数,默认 50.
问题:比如说我的模式是自动提交,自动提交间隔是 20 秒一次,那我消费了 10 个消息,很快一秒内就结束。但是这时候我自动提交时间还没到(那是不是意味着不会提交 offer),然后这时候我又去 poll 获取消息,会不会导致一直获取上一批的消息? 还是说如果 consumer 消费完了,自动提交时间还没到,如果你去 poll,这时候会自动提交,就不会出现重复消费的情况。
作者回复: 不会的。consumer 内部维护了一个指针,能够探测到下一条要消费的数据。
那到底 poll 的时候,获得了哪些数据?broker offset 后的数据?然后 consumer 再进行处理?
消费者事务
无论是自动提交还是手动提交,都可能出现消费完成,但是提交出现故障,从而导致重复消费的情况。
想要完成 kafka 消费者端的事务处理,需要将数据消费过程和偏移量提交过程进行原子性绑定,也就
是说数据处理完了,必须要保证偏移量正确提交,才可以做下一步的操作,如果偏移量提交失败,那么数据就恢复成处理之前的效果。
对于生产者事务而言,消费者消费的数据也会受到限制。默认情况下,消费者只能消费到生产者提交的数据,也就是未提交完成的数据,消费者是看不到的。如果想要消费到未提交的数据,需要更高消费事务隔离级别。默认使用 read_committed,也可以选择 read_uncommitted。
消费数据