Redis 应用场景
- 分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:分布式锁详解 。
- 限流:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。 - 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
- ……
Redis 实现分布式锁
Redis 实现消息队列
实际项目中使用 Redis 来做消息队列的非常少,毕竟有更成熟的消息队列中间件可以用。
先说结论:可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。
Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。
通过 RPUSH/LPOP 或者 LPUSH/RPOP即可实现简易版消息队列:
# 生产者生产消息
> RPUSH myList msg1 msg2
(integer) 2
> RPUSH myList msg3
(integer) 3
# 消费者消费消息
> LPOP myList
"msg1"
不过,通过 RPUSH/LPOP 或者 LPUSH/RPOP这样的方式存在性能问题,我们需要不断轮询去调用 RPOP 或 LPOP 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
因此,Redis 还提供了 BLPOP、BRPOP 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
# 超时时间为 10s
# 如果有数据立刻返回,否则最多等待10秒
> BRPOP myList 10
null
List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。
Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。
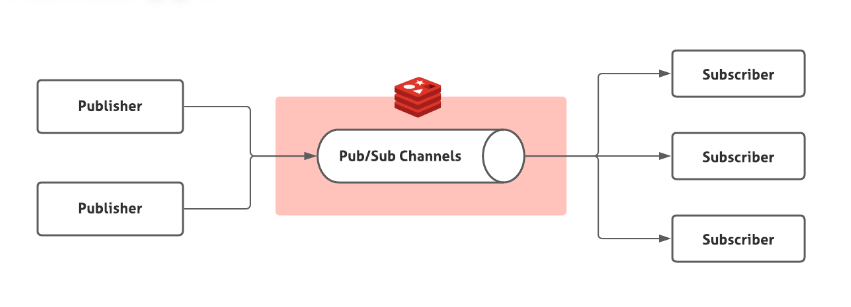
Redis 发布订阅 (pub/sub) 功能
pub/sub 中引入了一个概念叫 channel(频道),发布订阅机制的实现就是基于这个 channel 来做的。
pub/sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
- 发布者通过
PUBLISH投递消息给指定 channel。 - 订阅者通过
SUBSCRIBE订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
我们这里启动 3 个 Redis 客户端来简单演示一下:

pub/sub 实现消息队列演示
pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
为此,Redis 5.0 新增加的一个数据结构 Stream 来做消息队列。Stream 支持:
- 发布 / 订阅模式
- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念)
- 消息持久化( RDB 和 AOF)
- ACK 机制(通过确认机制来告知已经成功处理了消息)
- 阻塞式获取消息
Stream 的结构如下:
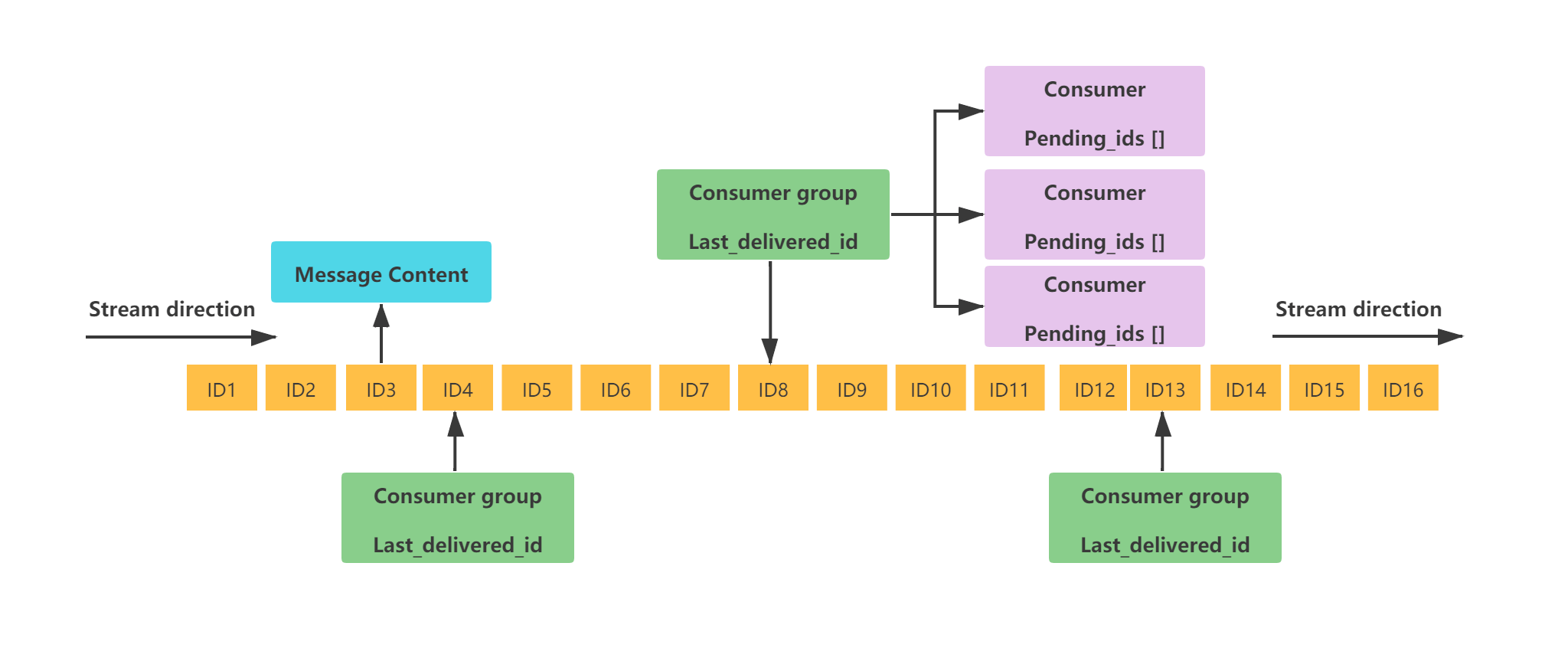
这是一个有序的消息链表,每个消息都有一个唯一的 ID 和对应的内容。ID 是一个时间戳和序列号的组合,用来保证消息的唯一性和递增性。内容是一个或多个键值对(类似 Hash 基本数据类型),用来存储消息的数据。
这里再对图中涉及到的一些概念,进行简单解释:
Consumer Group:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费last_delivered_id:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。pending_ids:记录已经被客户端消费但没有 ack 的消息的 ID。
下面是Stream 用作消息队列时常用的命令:
XADD:向流中添加新的消息。XREAD:从流中读取消息。XREADGROUP:从消费组中读取消息。XRANGE:根据消息 ID 范围读取流中的消息。XREVRANGE:与XRANGE类似,但以相反顺序返回结果。XDEL:从流中删除消息。XTRIM:修剪流的长度,可以指定修建策略(MAXLEN/MINID)。XLEN:获取流的长度。XGROUP CREATE:创建消费者组。XGROUP DESTROY: 删除消费者组XGROUP DELCONSUMER:从消费者组中删除一个消费者。XGROUP SETID:为消费者组设置新的最后递送消息 IDXACK:确认消费组中的消息已被处理。XPENDING:查询消费组中挂起(未确认)的消息。XCLAIM:将挂起的消息从一个消费者转移到另一个消费者。XINFO:获取流(XINFO STREAM)、消费组(XINFO GROUPS)或消费者(XINFO CONSUMERS)的详细信息。
Stream 使用起来相对要麻烦一些,这里就不演示了。
总的来说,Stream 已经可以满足一个消息队列的基本要求了。不过,Stream 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 Stream,这是目前相对最优的 Redis 消息队列实现。
相关阅读:Redis 消息队列发展历程 - 阿里开发者 - 2022。
Redis 实现搜索引擎
Redis 是可以实现全文搜索引擎功能的,需要借助 RediSearch ,这是一个基于 Redis 的搜索引擎模块。
RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
相比较于 Elasticsearch 来说,RediSearch 主要在下面两点上表现更优异一些:
- 性能更优秀:依赖 Redis 自身的高性能,基于内存操作(Elasticsearch 基于磁盘)。
- 较低内存占用实现快速索引:RediSearch 内部使用压缩的倒排索引,所以可以用较低的内存占用来实现索引的快速构建。
对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。
对于比较复杂或者数据规模较大的搜索场景还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
- 数据量限制:Elasticsearch 可以支持 PB 级别的数据量,可以轻松扩展到多个节点,利用分片机制提高可用性和性能。RedisSearch 是基于 Redis 实现的,其能存储的数据量受限于 Redis 的内存容量,不太适合存储大规模的数据(内存昂贵,扩展能力较差)。
- 分布式能力较差:Elasticsearch 是为分布式环境设计的,可以轻松扩展到多个节点。虽然 RedisSearch 支持分布式部署,但在实际应用中可能会面临一些挑战,如数据分片、节点间通信、数据一致性等问题。
- 聚合功能较弱:Elasticsearch 提供了丰富的聚合功能,而 RediSearch 的聚合功能相对较弱,只支持简单的聚合操作。
- 生态较差:Elasticsearch 可以轻松和常见的一些系统/软件集成比如 Hadoop、Spark、Kibana,而 RedisSearch 则不具备该优势。
Elasticsearch 适用于全文搜索、复杂查询、实时数据分析和聚合的场景,而 RediSearch 适用于快速数据存储、缓存和简单查询的场景。
Redis 延时队列
类似的问题:
- 订单在 10 分钟后未支付就失效,如何用 Redis 实现?
- 红包 24 小时未被查收自动退还,如何用 Redis 实现?
基于 Redis 实现延时任务的功能无非就下面两种方案:
- Redis 过期事件监听
- Redisson 内置的延时队列
Redis 过期事件监听的存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
Redisson 内置的延时队列具备下面这些优势:
- 减少了丢消息的可能:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
- 消息不存在重复消费问题:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
关于 Redis 实现延时任务的详细介绍,可以看我写的这篇文章:如何基于 Redis 实现延时任务?。