为什么设置过期时间
- Redis 内存资源宝贵
- 基于业务回答,验证码、用户 Token 过期实现方便
过期时间相关的命令
Redis 自带了给缓存数据设置过期时间的功能,比如:
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
(integer) 1
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
OK
127.0.0.1:6379> ttl key # 查看数据还有多久过期
(integer) 56
注意:Redis 中除了字符串类型有自己独有设置过期时间的命令 setex 外,其他方法都需要依靠 expire 命令来设置过期时间。另外, persist 命令可以移除一个键的过期时间。
Redis 如何判断数据是否过期
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
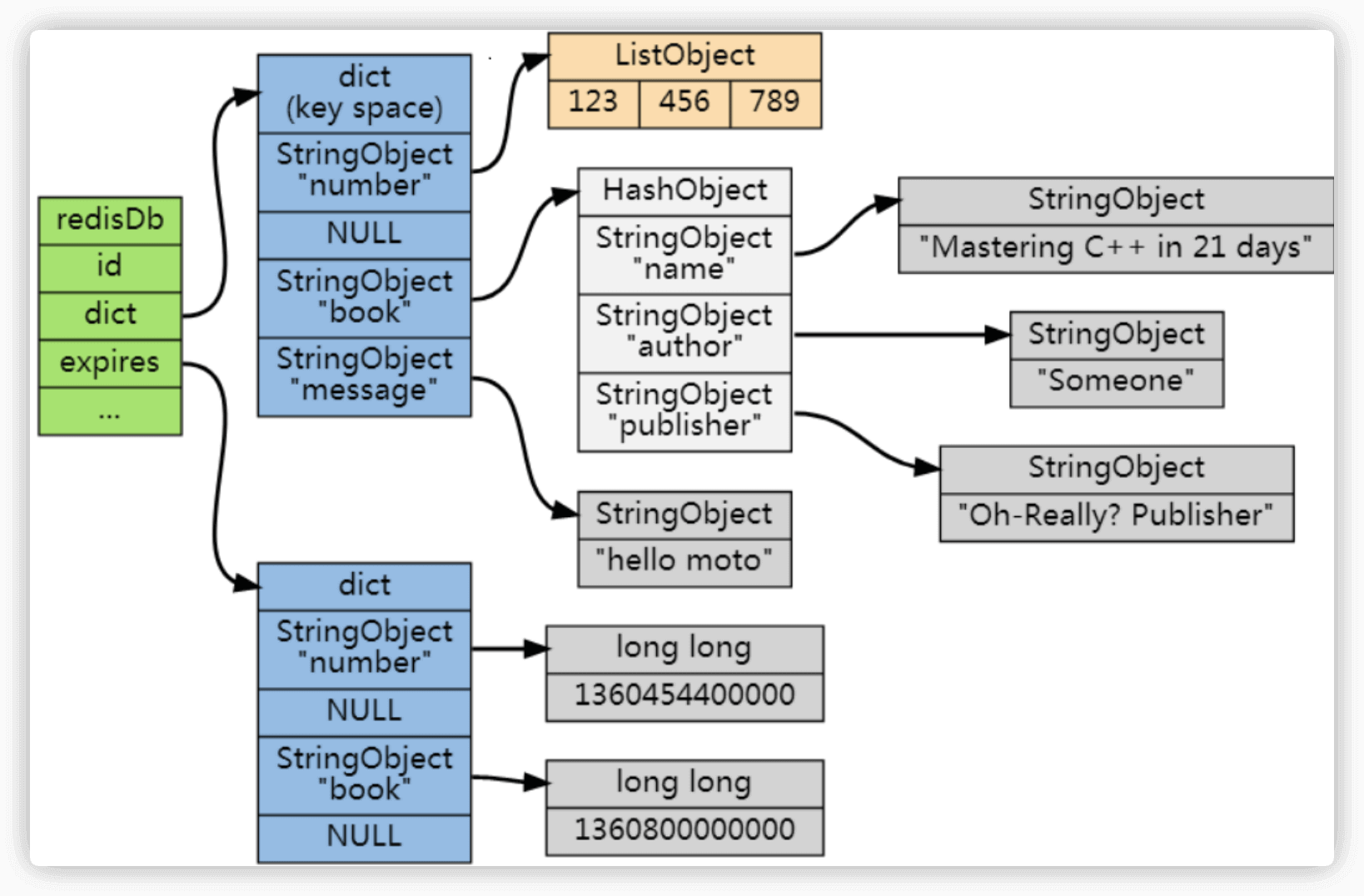
过期字典是存储在 redisDb 这个结构里的:
typedef struct redisDb {
...
dict *dict; //数据库键空间,保存着数据库中所有键值对
dict *expires // 过期字典,保存着键的过期时间
...
} redisDb;在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
过期数据删除策略
常用的过期数据的删除策略就下面这几种:
- 惰性删除:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
- 定期删除:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
- 延迟队列:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
- 定时删除:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
Redis 采用的那种删除策略呢?
Redis 采用的是 定期删除+惰性/懒汉式删除 结合的策略,这也是大部分缓存框架的选择。定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,结合起来使用既能兼顾 CPU 友好,又能兼顾内存友好。
下面是我们详细介绍一下 Redis 中的定期删除具体是如何做的。
Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。这也就解释了为什么有的 key 过期了,并没有被删除。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
另外,定期删除还会受到执行时间和过期 key 的比例的影响:
- 执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间。
- 如果这一批过期的 key 比例超过一个比例,就会重复执行此删除流程,以更积极地清理过期 key。相应地,如果过期的 key 比例低于这个比例,就会中断这一次定期删除循环,避免做过多的工作而获得很少的内存回收。
Redis 7.2 版本的执行时间阈值是 25ms,过期 key 比例设定值是 10%。
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which we do extra efforts. */每次随机抽查数量是多少?
expire.c 中定义了每次随机抽查的数量,Redis 7.2 版本为 20 ,也就是说每次会随机选择 20 个设置了过期时间的 key 判断是否过期。
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */如何控制定期删除的执行频率?
在 Redis 中,定期删除的频率是由 hz 参数控制的。hz 默认为 10,代表每秒执行 10 次,也就是每秒钟进行 10 次尝试来查找并删除过期的 key。
hz 的取值范围为 1~500。增大 hz 参数的值会提升定期删除的频率。如果你想要更频繁地执行定期删除任务,可以适当增加 hz 的值,但这会加 CPU 的使用率。根据 Redis 官方建议,hz 的值不建议超过 100,对于大部分用户使用默认的 10 就足够了。
下面是 hz 参数的官方注释,我翻译了其中的重要信息(Redis 7.2 版本)。

类似的参数还有一个 dynamic-hz,这个参数开启之后 Redis 就会在 hz 的基础上动态计算一个值。Redis 提供并默认启用了使用自适应 hz 值的能力,
这两个参数都在 Redis 配置文件 redis.conf 中:
# 默认为 10
hz 10
# 默认开启
dynamic-hz yes多提一嘴,除了定期删除过期 key 这个定期任务之外,还有一些其他定期任务例如关闭超时的客户端连接、更新统计信息,这些定期任务的执行频率也是通过 hz 参数决定。
为什么定期删除不是把所有过期 key 都删除呢?
这样会对性能造成太大的影响。如果我们 key 数量非常庞大的话,挨个遍历检查是非常耗时的,会严重影响性能。Redis 设计这种策略的目的是为了平衡内存和性能。
为什么 key 过期之后不立马把它删掉呢?这样不是会浪费很多内存空间吗?
因为不太好办到,或者说这种删除方式的成本太高了。假如我们使用延迟队列作为删除策略,这样存在下面这些问题:
- 队列本身的开销可能很大:key 多的情况下,一个延迟队列可能无法容纳。
- 维护延迟队列太麻烦:修改 key 的过期时间就需要调整期在延迟队列中的位置,并且,还需要引入并发控制。
Redis 内存淘汰策略
Redis 缓存最大值,根据场景变化,一般总数据量 15%-30%。
Redis 的内存淘汰策略只有在运行内存达到了配置的最大内存阈值时才会触发,这个阈值是通过 redis.conf 的 maxmemory 参数来定义的。64 位操作系统下,maxmemory 默认为 0 ,表示不限制内存大小。32 位操作系统下,默认的最大内存值是 3GB。
你可以使用命令 config get maxmemory 来查看 maxmemory 的值。
> config get maxmemory
maxmemory
0
- 默认 no-eviction,不删除数据。
- no-eviction:不驱逐数据,内存不足报错
- volatile-ttl:优先回收存活时间简短的键值对,仅限过期集合
- allkeys-random:尝试使用随机算法回收键值对
- volatile-random:尝试使用随机算法回收键值对,仅限过期集合
- allkeys-lru:尝试使用 LRU 算法回收最近最少使用键值对
- volatile-lru:尝试使用 LRU 算法回收最近最少使用键值对,仅限过期集合
- allkeys-lfu:回收最不经常使用 (频率) 的键值对
- volatile-lfu:回收最不经常使用 (频率) 的键值对,仅限过期集合
- lru 是淘汰最长时间没有被使用过的,lfu 是淘汰一段时间内使用最少的。
- 希望一些数据能长久保存,可以选择 volatile;希望设置过期时间,可以选择 ttl;数据访问频率大致相等,可以选择 random;部分频率高部分频率低,可以选择 lru-lfu。
- 优先
allkeys-lru,若访问频率差别不大,用allkeys-random。有置顶+过期要求,用volatile-lru。
Redis 提供了 6 种内存淘汰策略:
- volatile-lru(least recently used):从已设置过期时间的数据集(
server.db[i].expires)中挑选最近最少使用的数据淘汰。 - volatile-ttl:从已设置过期时间的数据集(
server.db[i].expires)中挑选将要过期的数据淘汰。 - volatile-random:从已设置过期时间的数据集(
server.db[i].expires)中任意选择数据淘汰。 - allkeys-lru(least recently used):从数据集(
server.db[i].dict)中移除最近最少使用的数据淘汰。 - allkeys-random:从数据集(
server.db[i].dict)中任意选择数据淘汰。 - no-eviction(默认内存淘汰策略):禁止驱逐数据,当内存不足以容纳新写入数据时,新写入操作会报错。
4.0 版本后增加以下两种:
- volatile-lfu(least frequently used):从已设置过期时间的数据集(
server.db[i].expires)中挑选最不经常使用的数据淘汰。 - allkeys-lfu(least frequently used):从数据集(
server.db[i].dict)中移除最不经常使用的数据淘汰。
allkeys-xxx 表示从所有的键值中淘汰数据,而 volatile-xxx 表示从设置了过期时间的键值中淘汰数据。
config.c 中定义了内存淘汰策略的枚举数组:
configEnum maxmemory_policy_enum[] = {
{"volatile-lru", MAXMEMORY_VOLATILE_LRU},
{"volatile-lfu", MAXMEMORY_VOLATILE_LFU},
{"volatile-random",MAXMEMORY_VOLATILE_RANDOM},
{"volatile-ttl",MAXMEMORY_VOLATILE_TTL},
{"allkeys-lru",MAXMEMORY_ALLKEYS_LRU},
{"allkeys-lfu",MAXMEMORY_ALLKEYS_LFU},
{"allkeys-random",MAXMEMORY_ALLKEYS_RANDOM},
{"noeviction",MAXMEMORY_NO_EVICTION},
{NULL, 0}
};
- 查看 Redis 内存淘汰策略:
config get maxmemory-policy - 当前 session 修改淘汰策略:
config set maxmemory-policy 内存淘汰策略 - 永久修改淘汰策略(需先重启):修改
redis.conf中的maxmemory-policy参数,如maxmemory-policy noeviction
关于淘汰策略的详细说明可以参考 Redis 官方文档:https://redis.io/docs/reference/eviction/。
Redis LRU 改进
Redis 对 LRU 算法做了简化,第一次决定淘汰数据时随机选择 N 个数据判断 LRU。后续淘汰时,将 lru 小于候选集合最小 lru 的放入集合中,当达到 N 个时,再淘汰。
LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
所以,在 Redis 中,LRU 算法被做了简化,以减轻数据淘汰对缓存性能的影响。具体来说,Redis 默认会记录每个数据的最近一次访问的时间戳(由键值对数据结构 RedisObject 中的 lru 字段记录)。然后,Redis 在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。
Redis 提供了一个配置参数 maxmemory-samples,这个参数就是 Redis 选出的数据个数 N。例如,我们执行如下命令,可以让 Redis 选出 100 个数据作为候选数据集:
CONFIG SET maxmemory-samples 100当需要再次淘汰数据时,Redis 需要挑选数据进入第一次淘汰时创建的候选集合。这儿的挑选标准是:能进入候选集合的数据的 lru 字段值必须小于候选集合中最小的 lru 值。当有新数据进入候选数据集后,如果候选数据集中的数据个数达到了 maxmemory-samples,Redis 就把候选数据集中 lru 字段值最小的数据淘汰出去。
这样一来,Redis 缓存不用为所有的数据维护一个大链表,也不用在每次数据访问时都移动链表项,提升了缓存的性能。
Redis LFU 改进
LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。
和那些被频繁访问的数据相比,扫描式单次查询的数据因为不会被再次访问,所以它们的访问次数不会再增加。因此,LFU 策略会优先把这些访问次数低的数据淘汰出缓存。这样一来,LFU 策略就可以避免这些数据对缓存造成污染了。
那么,LFU 策略具体又是如何实现的呢?既然 LFU 策略是在 LRU 策略上做的优化,那它们的实现必定有些关系。所以,我们就再复习下第 24 讲学习过的 LRU 策略的实现。
为了避免操作链表的开销,Redis 在实现 LRU 策略时使用了两个近似方法:
- Redis 是用 RedisObject 结构来保存数据的,RedisObject 结构中设置了一个 lru 字段,用来记录数据的访问时间戳;
- Redis 并没有为所有的数据维护一个全局的链表,而是通过随机采样方式,选取一定数量(例如 10 个)的数据放入候选集合,后续在候选集合中根据 lru 字段值的大小进行筛选。
在此基础上,Redis 在实现 LFU 策略的时候,只是把原来 24bit 大小的 lru 字段,又进一步拆分成了两部分。
- ldt 值:lru 字段的前 16bit,表示数据的访问时间戳;
- counter 值:lru 字段的后 8bit,表示数据的访问次数。
总结一下:当 LFU 策略筛选数据时,Redis 会在候选集合中,根据数据 lru 字段的后 8bit 选择访问次数最少的数据进行淘汰。当访问次数相同时,再根据 lru 字段的前 16bit 值大小,选择访问时间最久远的数据进行淘汰。
到这里,还没结束,Redis 只使用了 8bit 记录数据的访问次数,而 8bit 记录的最大值是 255,这样可以吗?
在实际应用中,一个数据可能会被访问成千上万次。如果每被访问一次,counter 值就加 1 的话,那么,只要访问次数超过了 255,数据的 counter 值就一样了。在进行数据淘汰时,LFU 策略就无法很好地区分并筛选这些数据,反而还可能会把不怎么访问的数据留存在了缓存中。
我们一起来看个例子。
假设第一个数据 A 的累计访问次数是 256,访问时间戳是 202010010909,所以它的 counter 值为 255,而第二个数据 B 的累计访问次数是 1024,访问时间戳是 202010010810。如果 counter 值只能记录到 255,那么数据 B 的 counter 值也是 255。
此时,缓存写满了,Redis 使用 LFU 策略进行淘汰。数据 A 和 B 的 counter 值都是 255,LFU 策略再比较 A 和 B 的访问时间戳,发现数据 B 的上一次访问时间早于 A,就会把 B 淘汰掉。但其实数据 B 的访问次数远大于数据 A,很可能会被再次访问。这样一来,使用 LFU 策略来淘汰数据就不合适了。
的确,Redis 也注意到了这个问题。因此,在实现 LFU 策略时,Redis 并没有采用数据每被访问一次,就给对应的 counter 值加 1 的计数规则,而是采用了一个更优化的计数规则。
简单来说,LFU 策略实现的计数规则是:每当数据被访问一次时,首先,用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1。
下面这段 Redis 的部分源码,显示了 LFU 策略增加计数器值的计算逻辑。其中,baseval 是计数器当前的值。计数器的初始值默认是 5(由代码中的 LFU_INIT_VAL 常量设置),而不是 0,这样可以避免数据刚被写入缓存,就因为访问次数少而被立即淘汰。
double r = (double)rand()/RAND_MAX;
...
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++; 使用了这种计算规则后,我们可以通过设置不同的 lfu_log_factor 配置项,来控制计数器值增加的速度,避免 counter 值很快就到 255 了。
为了更进一步说明 LFU 策略计数器递增的效果,你可以看下下面这张表。这是 Redis 官网上提供的一张表,它记录了当 lfu_log_factor 取不同值时,在不同的实际访问次数情况下,计数器的值是如何变化的。
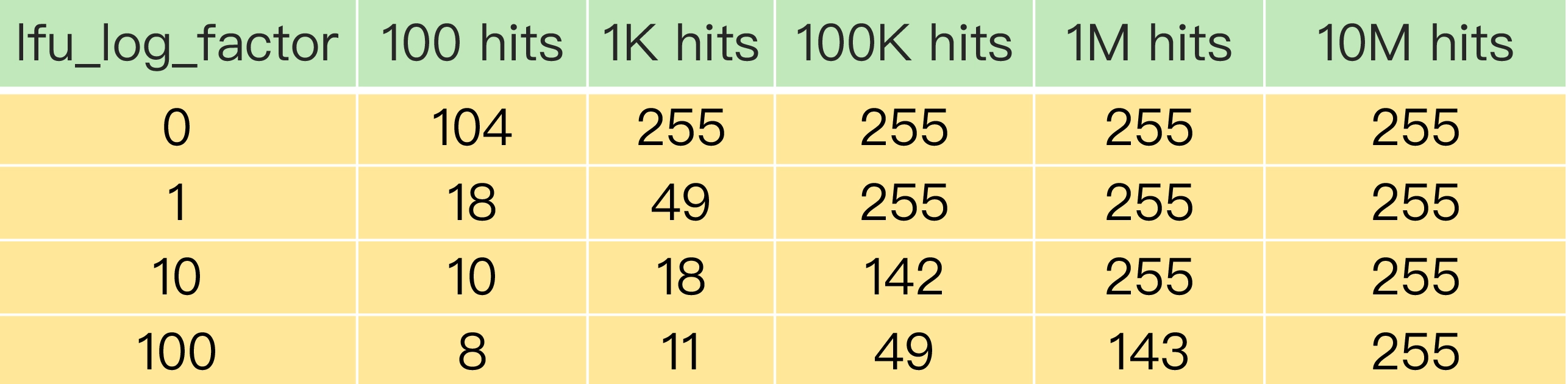
可以看到,当 lfu_log_factor 取值为 1 时,实际访问次数为 100K 后,counter 值就达到 255 了,无法再区分实际访问次数更多的数据了。而当 lfu_log_factor 取值为 100 时,当实际访问次数为 10M 时,counter 值才达到 255,此时,实际访问次数小于 10M 的不同数据都可以通过 counter 值区分出来。
正是因为使用了非线性递增的计数器方法,即使缓存数据的访问次数成千上万,LFU 策略也可以有效地区分不同的访问次数,从而进行合理的数据筛选。从刚才的表中,我们可以看到,当 lfu_log_factor 取值为 10 时,百、千、十万级别的访问次数对应的 counter 值已经有明显的区分了,所以,我们在应用 LFU 策略时,一般可以将 lfu_log_factor 取值为 10。
前面我们也提到了,应用负载的情况是很复杂的。在一些场景下,有些数据在短时间内被大量访问后就不会再被访问了。那么再按照访问次数来筛选的话,这些数据会被留存在缓存中,但不会提升缓存命中率。为此,Redis 在实现 LFU 策略时,还设计了一个 counter 值的衰减机制。
简单来说,LFU 策略使用衰减因子配置项 lfu_decay_time 来控制访问次数的衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。
简单举个例子,假设 lfu_decay_time 取值为 1,如果数据在 N 分钟内没有被访问,那么它的访问次数就要减 N。如果 lfu_decay_time 取值更大,那么相应的衰减值会变小,衰减效果也会减弱。所以,如果业务应用中有短时高频访问的数据的话,建议把 lfu_decay_time 值设置为 1,这样一来,LFU 策略在它们不再被访问后,会较快地衰减它们的访问次数,尽早把它们从缓存中淘汰出去,避免缓存污染。