为什么使用数据库(为什么不使用文件系统)
文件系统的弊端:
- 数据冗余
学校中在统计学生信息时会产生很多表,例如学生基本信息表格、学生数学成绩表格、学生英语成绩表格。在这些表格中存在着很多数据冗余,例如成绩表格中除了学生学号还有学生的姓名、班级等等。 - 数据不一致或修改困难
当学生的基本信息修改时,需要将何其有关的所有表格进行修改。表格众多修改困难,如果漏掉表格还会存在数据不一致的情况。 - 数据访问困难
表格与表格之间的联动性太差,想要进行联结查询,需要人工进行操作。 - 完整性约束问题
文件系统不一定存在完整性约束。 - 原子性问题
- 并发访问问题
- 安全问题
数据库与数据库管理系统
数据库相关的相关概念
- 数据库 : 数据库(DataBase 简称 DB)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合,它保存了一系列有组织的数据。
- 数据库管理系统 : 数据库管理系统(Database Management System 简称 DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
- 数据库管理员 : 数据库管理员(Database Administrator, 简称 DBA)负责全面管理和控制数据库系统。
- 数据库系统 : 数据库系统(Data Base System,简称 DBS)通常由软件、数据库和数据管理员(DBA)组成。
- SQL:结构化查询语言(Structured Query Language)专门用来与数据库通信的语言。
常见的数据库管理系统排名
DB-Engines Ranking - popularity ranking of database management systems
常见的数据库管理系统介绍
Oracle
1979 年,Oracle 2 诞生,它是第一个商用的 RDBMS(关系型数据库管理系统)。随着 Oracle 软件的名气越来越大,公司也改名叫 Oracle 公司。
SQL Server
SQL Server 是微软开发的大型商业数据库,诞生于 1989 年。C#、.net 等语言常使用,与 WinNT 完全集成,也可以很好地与 Microsoft BackOffice 产品集成。
DB2
IBM 公司的数据库产品, 收费的。常应用在银行系统中。
PostgreSQL
PostgreSQL 的稳定性极强,最符合 SQL 标准,开放源码,具备商业级 DBMS 质量。PG 对数据量大的文本以及 SQL 处理较快。
SQLite
嵌入式的小型数据库,应用在手机端。零配置,SQlite3 不用安装,不用配置,不用启动,关闭或者配置数据库实例。当系统崩溃后不用做任何恢复操作,再下次使用数据库的时候自动恢复。
MySQL 介绍
概述
- MySQL 是一个
开放源代码的关系型数据库管理系统,由瑞典 MySQL AB(创始人 Michael Widenius)公司 1995 年开发,迅速成为开源数据库的 No.1。 - MySQL 是可以定制的,采用了
GPL(GNU General Public License)协议,你可以修改源码来开发自己的 MySQL 系统。 - MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持
4GB,64 位系统支持最大的表文件为8TB。 - MySQL 使用
标准的SQL数据语言形式。 - MySQL 可以允许运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP 和 Ruby 等。
Oracle vs MySQL
Oracle 更适合大型跨国企业的使用,因为他们对费用不敏感,但是对性能要求以及安全性有更高的要求。
MySQL 由于其体积小、速度快、总体拥有成本低,可处理上千万条记录的大型数据库,尤其是开放源码这一特点,使得很多互联网公司、中小型网站选择了 MySQL 作为网站数据库(Facebook,Twitter,YouTube,阿里巴巴/蚂蚁金服,去哪儿,美团外卖,腾讯)。
关系型数据库设计规则
- 关系型数据库的典型数据结构就是
数据表,这些数据表的组成都是结构化的(Structured)。 - 将数据放到表中,表再放到库中。
- 一个数据库中可以有多个表,每个表都有一个名字,用来标识自己。表名具有唯一性。
- 表具有一些特性,这些特性定义了数据在表中如何存储,类似 Java 和 Python 中 “类”的设计。
表、记录、字段
- E-R(entity-relationship,实体-联系)模型中有三个主要概念是:
实体集、属性、联系集。 - 一个实体集(class)对应于数据库中的一个表(table),一个实体(instance)则对应于数据库表中的一行(row),也称为一条记录(record)。一个属性(attribute)对应于数据库表中的一列(column),也称为一个字段(field)。
表的关联关系
- 表与表之间的数据记录有关系(relationship)。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。
- 四种:一对一关联、一对多关联、多对多关联、自我引用
一对一关联
(one-to-one)
- 在实际的开发中应用不多,因为一对一可以创建成一张表。
- 举例:设计
学生表:学号、姓名、手机号码、班级、系别、身份证号码、家庭住址、籍贯、紧急联系人、…- 拆为两个表:两个表的记录是一一对应关系。
基础信息表(常用信息):学号、姓名、手机号码、班级、系别档案信息表(不常用信息):学号、身份证号码、家庭住址、籍贯、紧急联系人、…
- 两种建表原则:
- 外键唯一:主表的主键和从表的外键(唯一),形成主外键关系,外键唯一。
- 外键是主键:主表的主键和从表的主键,形成主外键关系。
一对多关系
(one-to-many)
- 常见实例场景:
客户表和订单表,分类表和商品表,部门表和员工表。 - 举例:
- 员工表:编号、姓名、…、所属部门
- 部门表:编号、名称、简介
- 一对多建表原则:在从表 (多方) 创建一个字段,字段作为外键指向主表 (一方) 的主键
多对多
(many-to-many)
要表示多对多关系,必须创建第三个表,该表通常称为 联接表,它将多对多关系划分为两个一对多关系。将这两个表的主键都插入到第三个表中。
举例 1:学生-课程
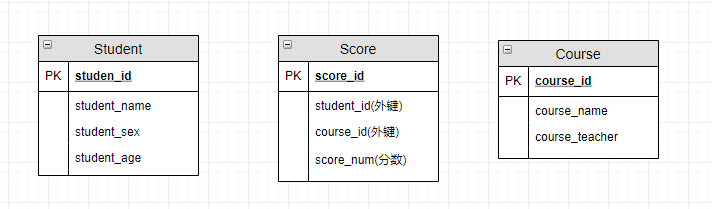
学生信息表:一行代表一个学生的信息(学号、姓名、手机号码、班级、系别…)课程信息表:一行代表一个课程的信息(课程编号、授课老师、简介…)选课信息表:一个学生可以选多门课,一门课可以被多个学生选择
举例 2:产品-订单
“订单”表和“产品”表有一种多对多的关系,这种关系是通过与“订单明细”表建立两个一对多关系来定义的。一个订单可以有多个产品,每个产品可以出现在多个订单中。
产品表:“产品”表中的每条记录表示一个产品。订单表:“订单”表中的每条记录表示一个订单。订单明细表:每个产品可以与“订单”表中的多条记录对应,即出现在多个订单中。一个订单可以与“产品”表中的多条记录对应,即包含多个产品。
自我引用
(Self reference)
数据库中的一些概念
元组, 码, 候选码, 主码, 外码, 主属性, 非主属性
- 关系:数据库的一张表。
- 元组 : 数据库表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。在二维表里,元组也称为行。
- 关系实例:一个关系的特定示例,即一组特定的行。
- 域:属性的范围。
- 码 :码就是能唯一标识实体的属性,对应表中的列。
- 候选码 : 若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
- 主码 : 主码也叫主键。主码是从候选码中选出来的。一个实体集中只能有一个主码,但可以有多个候选码。
- 外码 : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
- 主属性 : 候选码中出现过的属性称为主属性。比如关系工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
- 非主属性: 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
主键和外键的区别
- 主键(主码) :主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
- 外键(外码) :外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
ER 图概念
我们做一个项目的时候一定要试着画 ER 图来捋清数据库设计,这个也是面试官问你项目的时候经常会被问道的。
E-R 图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。它是描述现实世界关系概念模型的有效方法。是表示概念关系模型的一种方式。
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M:N)。另外,还有其他两种关系是:1 对 1(1:1)、1 对多(1:N)。
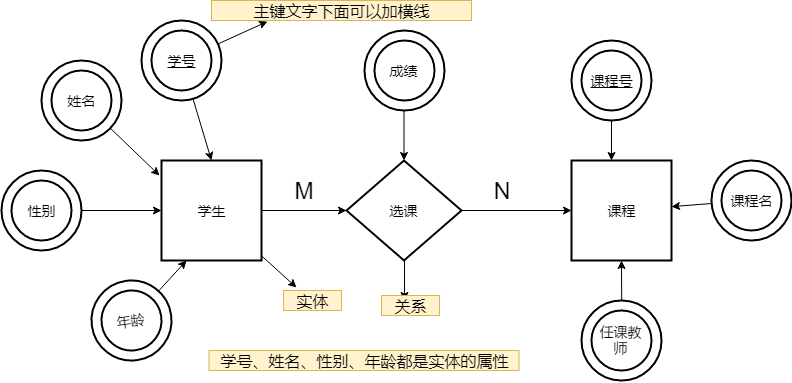
我们试着将上面的 ER 图转换成数据库实际的关系模型(实际设计中,我们通常会将任课教师也作为一个实体来处理):
数据库范式概念
1NF(第一范式)
属性(对应于表中的字段)不能再被分割。1NF 是所有关系型数据库的最基本要求,必须满足。例如,生日属性下又细分为年、月、日三个属性是不应该的。
2NF(第二范式)
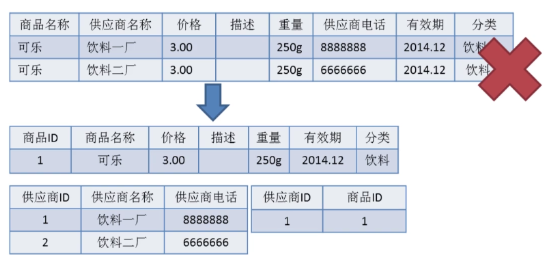
2NF 在 1NF 的基础之上,非码属性必须完全依赖于候选码,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
一些重要的概念:
- 函数依赖(functional dependency) :若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
- 部分函数依赖(partial functional dependency) :如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)→(姓名),(学号)→(姓名),(身份证号)→(姓名);所以姓名部分函数依赖与(学号,身份证号);
- 完全函数依赖(Full functional dependency) :在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)→(姓名),但是(学号)→(姓名)不成立,(班级)→(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
- 传递函数依赖 : 在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
3NF(第三范式)
3NF 在 2NF 的基础之上,任何非主属性不依赖于其它非主属性,消除了非主属性对于码的传递函数依赖。符合 3NF 要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。
总结
第一范式 1NF:属性不可再分。
第二范式 2NF:在 1NF 基础上,非码属性必须完全函数依赖于候选码,消除了非主属性对于码的部分函数依赖。。
第三范式 3NF:在 2NF 基础上,任何非主属性不依赖于其它非主属性,消除了非主属性对于码的传递函数依赖。
数据抽象
系统开发人员通过以下几个层次的抽象来对用户屏蔽复杂性:
- 物理层:数据是如何存储的
- 逻辑层:数据库中存储了什么数据 & 这些数据是什么关系。逻辑层用户不知道物理层的实现方式,称之为物理数据独立性。数据 CRUD 是如何实现的?
- 视图层:只描述数据库某个部分内容,系统可以给用户提供多个不同的视图。不同的用户也对应了不同的视图情况。
实例和模式
实例: 特定时刻存储在数据库中的数据集合。
模式: 数据库的总体设计。
根据不同的抽象层次,分为不同的模式:物理模式、逻辑模式、子模式。
数据模型
数据模型是一个描述数据、数据联系、数据语义以及一致性约束的概念工具的集合。
数据模式可以划分为四类:
- 关系模型
- 实体-联系模型
- 基于对象的数据模型
- 半结构化数据模型