微信红包的系统流程
包:生成发红包单号 → 写发红包订单 → 微信支付下单
发:微信支付 → 更新发红包订单 → 写发放记录 → 发温馨消息
抢:查发红包订单
拆:查发红包订单 → 计算红包金额 → 写领取订单 → 更新发红包订单 → 写领取记录 → 转零钱 → 更新领取单
微信红包的两大业务特点与技术难点
微信群红包类似于秒杀活动,包红包 = 发布秒杀,抢红包 = 秒杀动作。
但是在过年期间,微信群红包比秒杀活动更具特色的不同在于:
- 微信红包业务比普通商品“秒杀”有更海量的并发要求。同一时刻,全国上下可能有数万个群在发红包,以及群内用户的抢红包。而且,这样的海量并发会持续很长时间,秒杀活动一般只在整点进行。
- 微信红包业务要求更严格的安全级别。微信红包业务本质上是资金交易。微信红包是微信支付的一个商户,提供资金流转服务。用户发红包时,相当于在微信红包这个商户上使用微信支付购买一笔“钱”,并且收货地址是微信群。当用户支付成功后,红包“发货”到微信群里,群里的用户拆开红包后,微信红包提供了将“钱”转入折红包用户微信零钱的服务。秒杀活动支持超卖、少卖,但是微信群红包不能出现这种情况,即 100 块红包发放完,所有人获得的总和不等于 100 块。
上述两个特点带来了微信红包的两个技术难度:
-
事务级操作量级大。上文介绍微信红包业务特点时提到,普遍情况下同时会有数以万计的微信群在发红包。这个业务特点映射到微信红包系统设计上,就是有数以万计的“并发请求抢锁”同时在进行。这使得 DB 的压力比普通单个商品“库存”被锁要大很多倍。
-
事务性要求严格。微信红包系统本质上是一个资金交易系统,相比普通商品“秒杀”系统有更高的事务级别要求。
常见高并发解决方案
内存操作替代数据库操作
比如,所有的操作都在 Redis 中完成,然后将操作异步同步给 DB 中。
这样存在的问题是,在内存操作成功但 DB 持久化失败,或者内存 Cache 故障的情况下,DB 持久化会丢数据,不适合微信红包这种资金交易系统。
乐观锁代替悲观锁
乐观锁的具体应用方法,是在 DB 的“库存”记录中维护一个版本号。在更新“库存”的操作进行前,先去 DB 获取当前版本号。在更新库存的事务提交时,检查该版本号是否已被其他事务修改。如果版本没被修改,则提交事务,且版本号加 1;如果版本号已经被其他事务修改,则回滚事务,并给上层报错。
这样的问题在于:
- 并发抢到同一个版本号时,只有一个用户能成功,其他人都会失败,用户报错,体验不佳。若采用重试机制,会增加服务器的负担。
- 如果采用乐观锁,将会导致第一时间同时拆红包的用户有一部分直接返回失败,反而那些“手慢”的用户,有可能因为并发减小后拆红包成功,这会带来用户体验上的负面影响。
- 如果采用乐观锁的方式,会带来大数量的无效更新请求、事务回滚,给 DB 造成不必要的额外压力。
微信红包系统高并发解决方案
系统垂直 SET 化,分而治之
微信红包用户发一个红包时,微信红包系统生成一个 ID 作为这个红包的唯一标识。接下来这个红包的所有发红包、抢红包、拆红包、查询红包详情等操作,都根据这个 ID 关联。
对于存储层来说,早期的架构设计特点为:
- 订单顺序生成。使用序列号服务生成唯一 ID。
- 按订单号末三位分库表。可以分一百个逻辑库,每个逻辑库含有十张表。
- 多组物理 DB 均匀分配库表。一百个逻辑库均匀地分布到十组物理 DB,每组 DB 存十个逻辑库。
- 所有 DB 共用同一接入层。
这样存在的问题是:
- DB 性能瓶颈引发服务瓶颈。一组 DB 的性能出现瓶颈时,数据操作变慢, 拆红包的事务操作在 MYSQL 排队等待。由于所有十组 DB 机器与所有的订单 SERVER 连接,导致所有的订单 SERVER 都被拖住,从而影响红包整体的可用性。
- 存储机器故障影响放大。
- 扩缩容问题。
为解决 DB 间的相互影响,需要将 DB 间相互隔离,订单存储层 SET 化。红包系统根据这个红包 ID,按一定的规则(如按 ID 尾号取模等),垂直上下切分。切分后,一个垂直链条上的逻辑 Server 服务器、DB 统称为一个 SET。
各个 SET 之间相互独立,互相解耦。并且同一个红包 ID 的所有请求,包括发红包、抢红包、拆红包、查详情详情等,垂直 stick 到同一个 SET 内处理,高度内聚。通过这样的方式,系统将所有红包请求这个巨大的洪流分散为多股小流,互不影响,分而治之,如下图所示。当一组 DB 出现故障,只会影响该组 DB 对应的 SERVER。
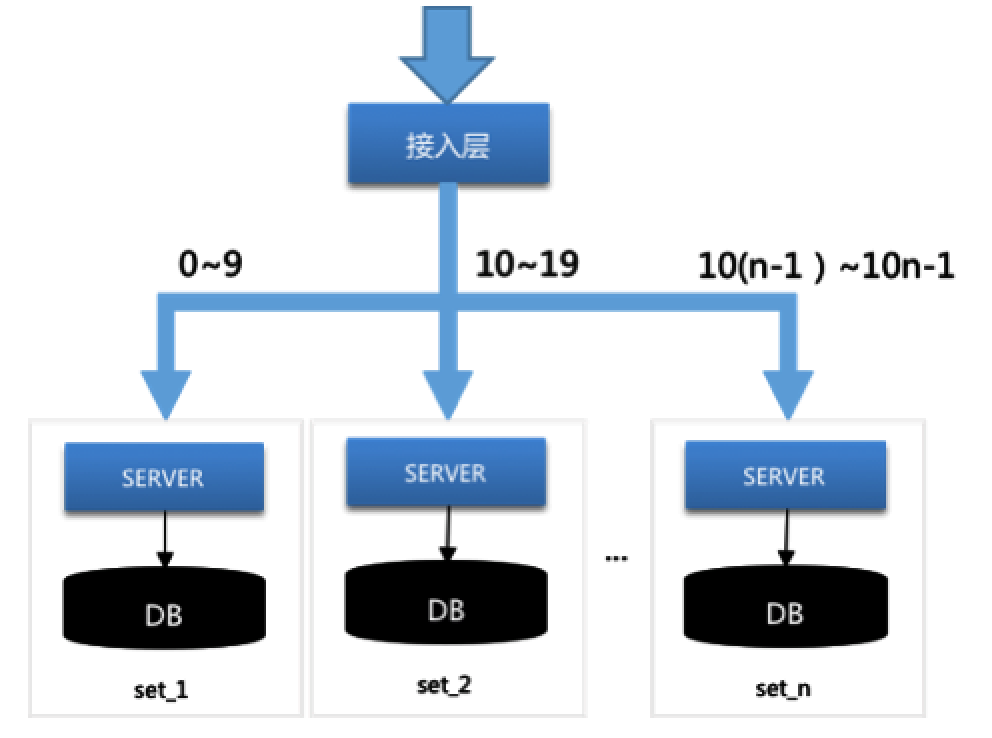
业务逻辑层为什么不一起 SET 化?业务逻辑层承载了用户维度相关的业务操作,不可以按照订单的维度分业务逻辑,例如务逻辑层会请求用户的头像、昵称等,如果继续按照订单分业务逻辑,会导致跨地域调用。
微信红包系统采取的方案是,在订单 SERVER 服务端增加快速拒绝服务的能力。SERVER 主动监控 DB 的性能情况,DB 性能下降、自身的 CPU 使用升高,或者发现其他的监控维度超标时,订单 SERVER 直接向上层报错,不再去访问 DB,以此保证业务逻辑层的可用性。
逻辑 Server 层将请求排队,解决 DB 并发问题
为了使拆红包的事务操作串行地进入 DB,只需要将请求在 Server 层以 FIFO(先进先出)的方式排队,就可以达到这个效果。从而问题就集中到 Server 的 FIFO 队列设计上。
微信红包系统设计了分布式的、轻巧的、灵活的 FIFO 队列方案。其具体实现如下:
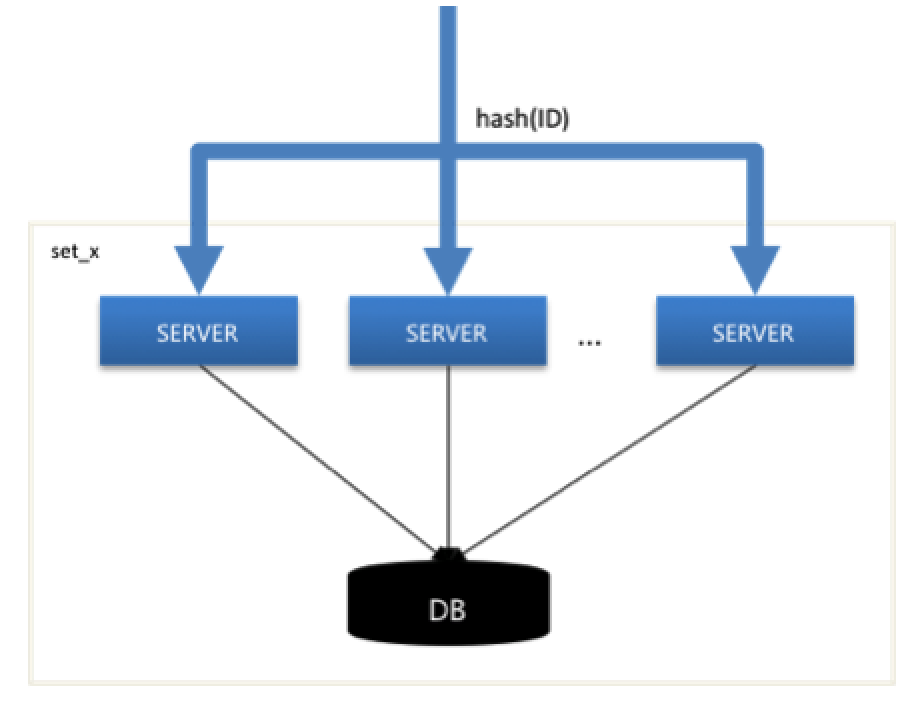
首先,将同一个红包 ID 的所有请求 stick 到同一台 Server。
上面 SET 化方案已经介绍,同个红包 ID 的所有请求,按红包 ID stick 到同个 SET 中。不过在同个 SET 中,会存在多台 Server 服务器同时连接同一台 DB(基于容灾、性能考虑,需要多台 Server 互备、均衡压力)。
为了使同一个红包 ID 的所有请求,stick 到同一台 Server 服务器上,在 SET 化的设计之外,微信红包系统添加了一层基于红包 ID hash 值的分流,如下图所示。
其次,设计单机请求排队方案。
将 stick 到同一台 Server 上的所有请求在被接收进程接收后,按红包 ID 进行排队。然后串行地进入 worker 进程(执行业务逻辑)进行处理,从而达到排队的效果,如下图所示。
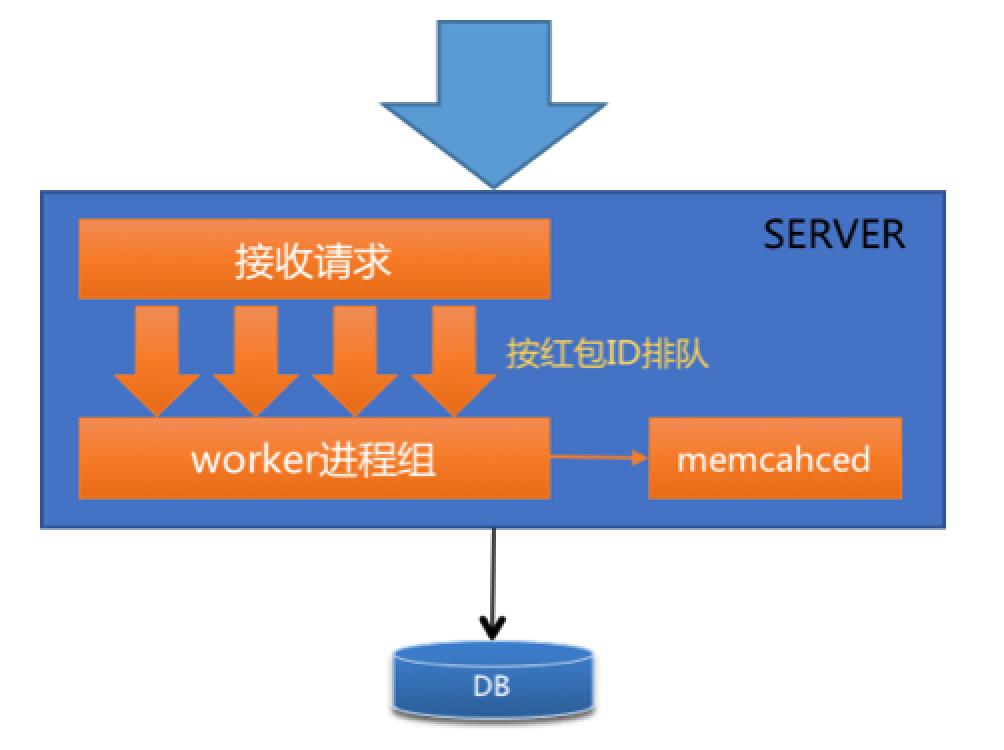
最后,增加 memcached 控制并发。
为了防止 Server 中的请求队列过载导致队列被降级,从而所有请求拥进 DB,系统增加了与 Server 服务器同机部署的 memcached,用于控制拆同一个红包的请求并发数。
具体来说,利用 memcached 的 CAS 原子累增操作,控制同时进入 DB 执行拆红包事务的请求数,超过预先设定数值则直接拒绝服务。用于 DB 负载升高时的降级体验。
通过以上三个措施,系统有效地控制了 DB 的“并发抢锁”情况。
双维度库表设计,保障系统性能稳定
红包系统的分库表规则,初期是根据红包 ID 的 hash 值分为多库多表。随着红包数据量逐渐增大,单表数据量也逐渐增加。而 DB 的性能与单表数据量有一定相关性。当单表数据量达到一定程度时,DB 性能会有大幅度下降,影响系统性能稳定性。采用冷热分离,将历史冷数据与当前热数据分开存储,可以解决这个问题。
处理微信红包数据的冷热分离时,系统在以红包 ID 维度分库表的基础上,增加了以循环天分表的维度,形成了双维度分库表的特色。
具体来说,就是分库表规则像 db_xx.t_y_dd 设计,其中,xx/y 是红包 ID 的 hash 值后三位,dd 的取值范围在 01~31,代表一个月天数最多 31 天。
通过这种双维度分库表方式,解决了 DB 单表数据量膨胀导致性能下降的问题,保障了系统性能的稳定性。同时,在热冷分离的问题上,又使得数据搬迁变得简单而优雅。
这里简单的说就是,一般红包发出三天后,99% 的用户不会再去点开这个红包了。因此微信红包系统采取按时间做冷热数据分离,降低数据的存储成本,同时提升了热数据的访问性能。
综上所述,微信红包系统在解决高并发问题上的设计,主要采用了 SET 化分治、请求排队、双维度分库表等方案,使得单组 DB 的并发性能提升了 8 倍左右,取得了很好的效果。
微信红包可用性方案
在可用性方面,除了保证一定的高并发能力,还需要少的出现故障。
业务逻辑层 - 部署方案设计
首先是业务逻辑层的部署方案。业务逻辑层是无状态的,微信红包系统的业务逻辑层,部署在两个城市,即两地部署,每一个城市部署至少三个园区,即三个 IDC。并且每个服务需要保证三个 IDC 的部署均衡。另外,三个 IDC 总服务能力需要冗余三分之一,当一个 IDC 出现故障时,服务能力仍然足够。从而达到 IDC 故障不会对可用性产生影响。
业务逻辑层 - 异步化设计
微信红包的某些步骤不实时完成也不会影响用户对红包业务可用性的体验。在“发红包”环节,“写发放记录”并不需要实时的。在“拆红包”环节,“写领取记录”、“转零钱”等也不需要实时的。
用户抢到红包时,一般不会实时去钱包查看微信零钱,而是在微信群中点开消息查看本次抢到金额和他人抢红包金额。所以拆红包时只需要从 cache 查询用户是否拆过红包,然后写入拆红包的订单记录,更新发红包订单,其他的操作都可以异步化。当然,不是每个业务都可以进行异步化设计,需要进行业务分析,判断是否存在非关键步骤之外的事情可以将其异步化,并通过异步对账保证最终一致。
订单存储层 - 故障自愈
完成 SET 化之后,DB 故障仍对业务有十分之一影响,那么这十分之一该怎么解决?通过对系统进行研究分析之后,发现 DB 可以做到故障自愈。
假设尾号 90-99 的 SET 故障时,如果业务逻辑服务后续不再生成属于这个 SET 的订单,那后续的业务就可以逐渐恢复。
也就是在发生故障时,业务逻辑层发布一个版本,屏蔽故障号段的单号生成,就可以恢复业务。进一步想,除了人为发版本,有没有方法可以让 DB 故障时自动恢复?在 DB 故障导致业务失败时,业务逻辑层可获取到故障 DB 的号段,在发红包时,将这些故障的号段,换一个可用的号段就可恢复业务。订单号除了最后三位,前面的部分已能保证该红包唯一性,后面的数字只代表着分库表信息,故障时只需要将最后三位换另外一个 SET 便可自动恢复。
完成这个设计后,即使 DB 出现故障,业务的可用性也不会有影响。这里还有一点,新的发红包请求可避免 DB 故障的影响,但那些故障之前已发出未被领取的红包,红包消息已发送到微信群,单号已确定,拆红包时还是失败。对这种情况,由于不会有增量,采用正常的主备切换解决即可。
平行扩缩容设计
红包系统按红包单号后面两个数字分多 SET,为了使扩容后数据保持均衡,扩容只能由 10 组 DB 扩容到 20 组、50 组或者 100 组。另外,这个扩容方式,过程也比较复杂。首先,数据要先从旧数据库同步复制到新扩容的 DB,然后部署 DB 的接入 SERVER,最后在凌晨业务低峰时停服扩容。
这个扩容方式的复杂性,根本原因是数据需要从旧 SET 迁到新 SET。如果新产生数据与旧数据没关系,那么就可以省掉这部分的迁移动作,不需停服输。
分析发现,需要把旧数据迁出来的原因是订单号段 00-99 已全部被用,每个物理数据库包含了 10 个逻辑库。如果将订单号重新设计,预留三位空间,三位数字每一个代表独立的物理 DB,原来 10 组 DB 分别为 000-009 号段。
这种设计,缩容时,比如要缩掉 000 这组,只需在业务逻辑服务上不生成订单号为 000 的红包订单。扩容时,比如扩为 11 组,只需多生成 010 的订单号,这个数据便自动写入新 DB。当然,缩容需要一个前提条件,也就是冷热分离,缩容后数据变为冷数据,可下线热数据机器。以上就是红包的平行扩缩容方案。
简单的说就是,最开始是
红包 ID + 2 位逻辑库 ID + 1 位分表组成,更改为红包 ID + 3 位逻辑库 ID + 1 位分表。在最开始的时候,还是按照 000-009 号段使用。如果要扩容,那么就增加一个 010 的订单号,就自动将数据写入新的 DB 了。如果要缩容,如缩 000,业务逻辑服务上不生成 000 的订单号就完成了。缩容后数据变为冷数据,可下线热数据机器。这样的方式,避免了原本扩容时,需要将所有数据从旧 DB 拷贝到新 DB 的迁移动作。