需求背景
vivo 商城发展及用户量提升,优惠券与商城耦合在一个系统内,导致很多问题:
- 海量优惠券发放,打到优惠券单库、单表存储瓶颈
- 与商城系统高度耦合,直接影响了商城整站接口性能
- 优惠券的迭代更新受限于商城的版本安排
- 针对多品类优惠券,技术层面没有沉淀通用优惠券能力
vivo 商品优惠券的场景有:
- 常见的优惠券促销玩法
- 以优惠券的形式作为其他一些活动或资产的载体,比如手机类商品的保值换新、内购福利、与外部广告商合作发放优惠券等。
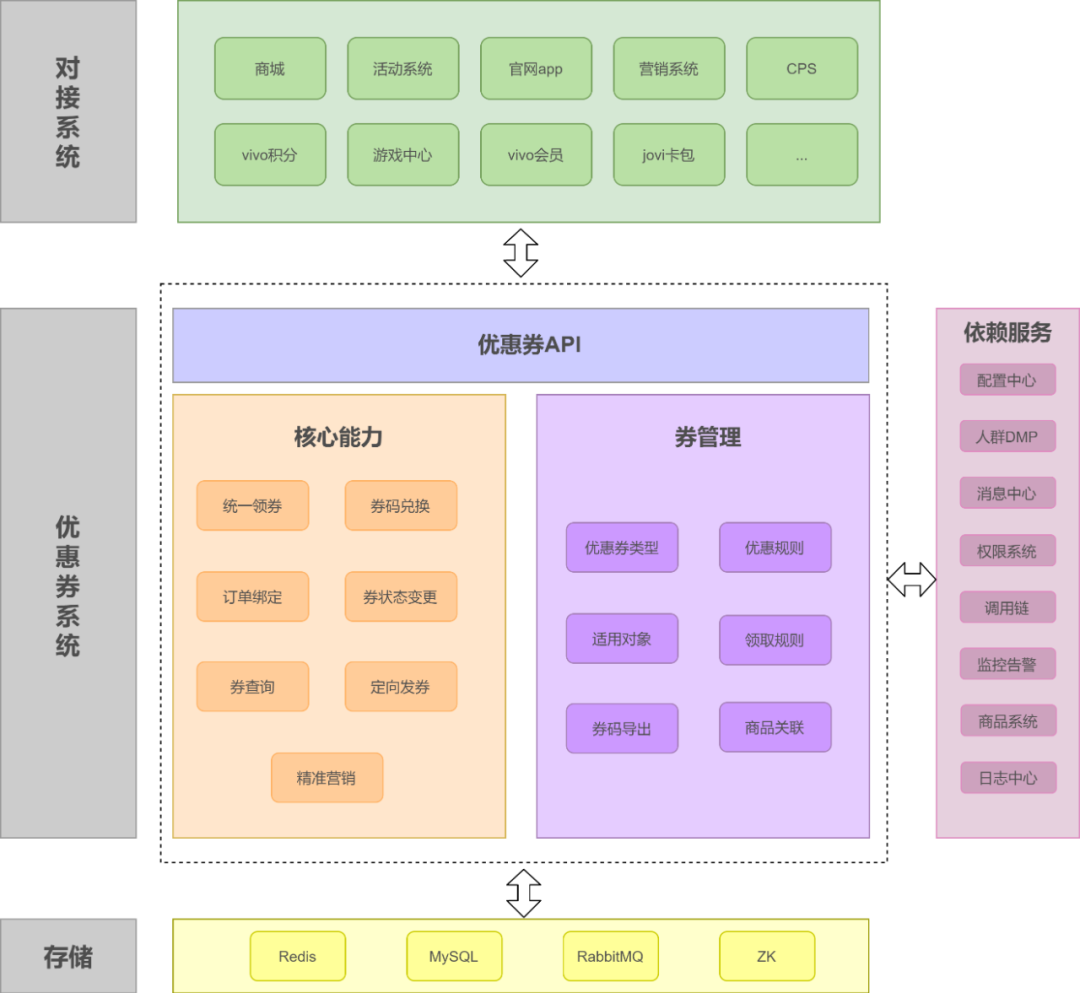
系统架构
系统迁移方案
vivo 采用不停机系统迁移
- 迁移前,运营停止与优惠券相关的后台操作,避免产生优惠券静态数据。
静态数据:优惠券后台生成的数据,与用户无关。
动态数据:与用户有关的优惠券数据,含用户领取的券、券和订单的关系数据等。
-
配置当前数据库开关为单写,即优惠券数据写入商城库(旧库)。
-
优惠券系统上线,通过脚本迁移静态数据。迁完后,验证静态数据迁移准确性。
-
配置当前数据库开关为双写,即线上数据同时写入商城库和优惠券新库。此时服务提供的数据源依旧是商城库。
-
迁移动态数据。迁完后,验证动态数据迁移准确性。
-
切换数据源,服务提供的数据源切换到新库。验证服务是否正确,出现问题时,切换回商城数据源。
-
关闭双写,优惠券系统迁移完成。
系统设计
优惠券分库分表
单表已经达到瓶颈,对用户优惠券数据进行分库分表。
采用了公司中间件团队提供的自研框架。原理是引入自研的 MyBatis 的插件,根据自定义的路由策略计算不同的库表后缀,定位至相应的库表。
用户优惠券与用户 id 关联,并且用户 id 是贯穿整个系统的重要字段,因此使用用户 id 作为分库分表的路由因子。这样可以保证同一个用户路由至相同的库表,既有利于数据的聚合,也方便用户数据的查询。
假设共分 N 个库 M 个表,分库分表的路由策略为:
库后缀 databaseSuffix = hash(userId) / M % N
表后缀 tableSuffix = hash(userId) % M
优惠券发放方式设计
为满足各种不同场景的发券需求,优惠券系统提供三种发券方式:统一领券接口、后台定向发券、券码兑换发放。
统一领券接口
保证领券校验的准确性:检验 + 分布式锁检验重复领取
优惠券资格校验:领取对象、各种限制条件、库存和领取数量的校验、重复领券的校验。
优惠券采用的是分布式锁方案,分布式锁的实现依赖于 Redis。在校验用户领券数量前先尝试获取分布式锁,优惠券发放成功后释放锁,保证用户领取同一张券时不会出现超领。上面这种场景,用户第一次请求成功获取分布式锁后,直至第一次请求成功释放已获取的分布式锁或超时释放,不然用户第二次请求会获取分布式锁失败,这样保证 A 用户只会成功领取一张。
库存扣减:DB 扣减 + 拆库存
领券要进行库存扣减,常见库存扣减方案有两种:DB 扣减、Redis 扣减。
从优惠券系统当前及可预见未来的流量峰值、系统维护性、实用性上综合考虑,优惠券系统采用了 DB 扣减库存。除此之外,进行了库存的拆分,会将库存平均分配成 M 份,初始化更新到库存记录表中。用户领券,随机选取库存记录表中已分配的某一库存字段(共 M 个)进行更新,更新成功即为库存扣减成功。同时,定时任务会定期同步已领取的库存数。
一键领取多张券
用户可以一键领取多张不同类型的券,因此统一领券接口需要支持用户一键领券,除了领取同一券模板的多张,也支持领取不同券模板的多张。
实现上需要注意:
- 如何保证性能问题。券数目增多后,每张券分别进行校验、库存扣减、入库,那么性能会下降。
- 方案一,批量操作。批量入库可以保证与数据库的 IO 的次数只有一次,不受券的数量影响。如上所述,用户优惠券数据做了分库分表,同一用户的优惠券资产保存在同一库表中,因此同一用户可实现批量入库。
- 方案二,限制单次领券数量。设置阀值,超出数量后,直接返回,保证系统在安全范围内。
- 高并发情况下,用户超领问题。用户在商城发起请求,一键领取 A/B/C/D 四张券,同时活动系统给用户发放券 A,这两个领券请求是同时的。其中,券 A 限制了每个用户只能领取一张。
- 假设采用分布式锁校验准确性,分布式锁的 key 为:
用户 id+A_id+B_id+C_id+D_id和用户 id+A_id。那么分布式锁没有发挥作用。 - 在批量领券的时候,更改为
用户 id+A_id、用户 id+B_id、…… 等批量获取 4 个分布式锁。任意失败,则需要自旋等待(在超时时间内)。获取所有的分布式锁成功,才可以进行下一步。
- 假设采用分布式锁校验准确性,分布式锁的 key 为:
🤔 这里怎么没考虑大家都批量领取时,校验券数量是否足够?如果是分布式锁校验,那么高并发下性能较差。如果不用分布式锁,容易出现死锁?或者按照券 ID 顺序对 DB 加锁校验,那性能是否也比较差?
或者假定批量领取的,都不是限量的券。
接口幂等性
幂等性的实现有多种方案,优惠券系统利用数据库的唯一索引来保证幂等。
在哪个表来添加唯一索引呢?无非两种方案:现有的表或者新建表。
- 采用现有的表,不需要增加表的关联。但如上所述,因为做了分库分表,大量的表需要添加唯一字段,并且需要兼容历史数据,需要保证历史数据新增字段的唯一性。
- 采用新建表这种方式,不需要兼容历史数据,但缺陷也很明显,增加了一层表的关联,对性能和现有逻辑都有很大影响。
综合考虑,我们选取了在现有表添加唯一字段这种方式,这样更利于保证性能和后续的维护性。
怎么兼容历史数据和业务方?采用脚本刷数据的方式,构造唯一值并刷新到每一行历史数据中。
定向发券
定向发券用于运营在后台针对特定人群进行发券。定向发券可以弥补用户主动领券,人群覆盖不精准、覆盖面不广的问题。通过定向发券,可以精准覆盖特定人群,提高下单转化率。在大促期间,大范围人群的定向发券还可以承载活动 push 和降价促销双重任务。
定向发券不同于用户主动领券,定向发券的量通常会很大(亿级)。为了支撑大批量的定向发券,定向发券做了一些优化:
1)去除事务。事务逻辑过重,对于定向发券来说没必要。发券失败,记录失败的券,保证失败可以重试。
2)轻量化校验。定向发券限制了券类型,通过限制配置的方式规避需严格校验属性的配置。不同于用户主动领券校验逻辑的冗长,定向发券的校验非常轻量,大大提升发券性能。
3)批量插入。批量券插入减少数据库 IO 次数,消除数据库瓶颈,提升发券速度。定向发券是针对不同的用户,用户优惠券做了分库分表,为了实现批量插入,需要在内存中先计算出不同用户对应的库表后缀,数据归集后再批量插入,最多插入 M 次,M 为库表总个数。
4)核心参数可动态配置。比如单次发券数量,单次读库数量,发给消息中心的消息体包含的用户数量等,可以控制定向发券的峰值速度和平均速度。
券码兑换
站外营销券的发放方式与其他券不同,通过券码进行兑换。券码由后台导出,通过短信或者活动的方式发放到用户,用户根据券码兑换后获取相应的券。券码的组成有一定的规则,在规则的基础上要保证安全性,这种安全性主要是券码校验的准确性,防止已兑换券码的再次兑换和无效券码的恶意兑换。
精细化营销能力设计
通过标签组合配置的方式,优惠券提供精细化营销的能力,以实现优惠券的千人千面。标签可分为准实时和实时,值得注意的是,一些实时的标签的处理需要前提条件,比如地区属性需要用户授权。
券和商品之间的关系
优惠券的使用需要和商品关联,可关联所有商品,也可以关联部分商品。为了灵活性地满足运营对于券关联商品的配置,优惠券系统有两种关联方式:
a. 黑名单。可用商品 = 全部商品 - 黑名单商品。
黑名单适用于券的可使用商品范围比较广这种情况,全部商品排除掉黑名单商品就是券的可使用范围。
b. 白名单。可用商品 = 白名单商品。
白名单适用于券的可使用商品范围比较小这种情况,直接配置券的可使用商品。
除此以外,还有超级黑名单的配置,黑名单和白名单只对单个券有效,超级黑名单对所有券有效。当前优惠券系统提供商品级的关联,后续优惠券会支持商品分类维度的关联,分类维度 + 商品维度可以更灵活地关联优惠券和商品。
高性能保证
优惠券对接系统多,存在高流量场景,优惠券对外提供接口需保证高性能和高稳定性。
多级缓存、读写分离、对依赖外部接口做了隔离和熔断、用户维度优惠券字段冗余。