列表和元组的内部实现
先来看 Python 3.7 的 list 源码。你可以先自己阅读下面两个链接里的内容。
listobject.h:https://github.com/python/cpython/blob/949fe976d5c62ae63ed505ecf729f815d0baccfc/Include/listobject.h#L23
listobject.c: https://github.com/python/cpython/blob/3d75bd15ac82575967db367c517d7e6e703a6de3/Objects/listobject.c#L33

可以看到,list 本质上是一个 over-allocate 的 array。其中,ob_item 是一个指针列表,里面的每一个指针都指向列表的元素。而 allocated 则存储了这个列表已经被分配的空间大小。
需要注意的是,allocated 与列表实际空间大小的区别。列表实际空间大小,是指 len(list)返回的结果,即上述代码注释中的 ob_size,表示这个列表总共存储了多少个元素。实际情况下,为了优化存储结构,避免每次增加元素都要重新分配内存,列表预分配的空间 allocated 往往会大于 ob_size(详见正文中的例子)。
所以,它们的关系为:allocated >= len(list) = ob_size。
如果当前列表分配的空间已满(即 allocated == len(list)),则会向系统请求更大的内存空间,并把原来的元素全部拷贝过去。列表每次分配空间的大小,遵循下面的模式:
0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
下面是 Python 3.7 的 tuple 源码,同样的,你可以先自己阅读一下。
tupleobject.h: https://github.com/python/cpython/blob/3d75bd15ac82575967db367c517d7e6e703a6de3/Include/tupleobject.h#L25
tupleobject.c:https://github.com/python/cpython/blob/3d75bd15ac82575967db367c517d7e6e703a6de3/Objects/tupleobject.c#L16
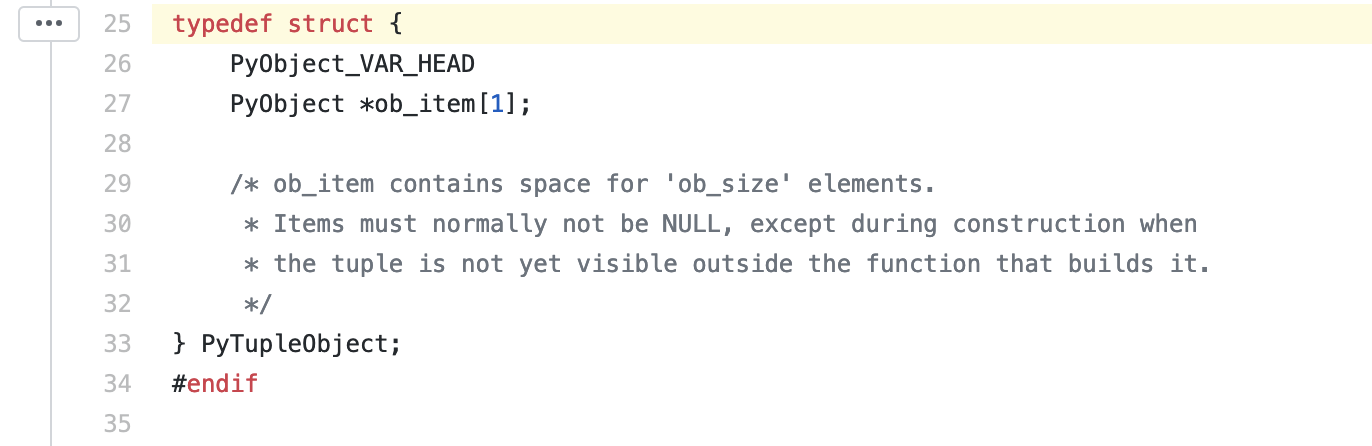
你可以看到,它和 list 相似,本质也是一个 array,但是空间大小固定。不同于一般 array,Python 的 tuple 做了许多优化,来提升在程序中的效率。
举个例子,当 tuple 的大小不超过 20 时,Python 就会把它缓存在内部的一个 free list 中。这样,如果你以后需要再去创建同样的 tuple,Python 就可以直接从缓存中载入,提高了程序运行效率。
哈希表的实现
我们可以先来看旧哈希表的示意图:
--+-------------------------------+
| 哈希值 (hash) 键 (key) 值 (value)
--+-------------------------------+
0 | hash0 key0 value0
--+-------------------------------+
1 | hash1 key1 value1
--+-------------------------------+
2 | hash2 key2 value2
--+-------------------------------+
. | ...
__+_______________________________+你会发现,它是一个 over-allocate 的 array,根据元素键(key)的哈希值,来计算其应该被插入位置的索引。
因此,假设我有下面这样一个字典:
{'name': 'mike', 'dob': '1999-01-01', 'gender': 'male'}那么这个字典便会存储为类似下面的形式:
entries = [
['--', '--', '--']
[-230273521, 'dob', '1999-01-01'],
['--', '--', '--'],
['--', '--', '--'],
[1231236123, 'name', 'mike'],
['--', '--', '--'],
[9371539127, 'gender', 'male']
]
这里的’---‘,表示这个位置没有元素,但是已经分配了内存。
我们知道,当哈希表剩余空间小于 1/3 时,为了保证相关操作的高效性并避免哈希冲突,就会重新分配更大的内存。所以,当哈希表中的元素越来越多时,分配了内存但里面没有元素的位置,也会变得越来越多。这样一来,哈希表便会越来越稀疏。
而新哈希表的结构,改变了这一点,也大大提高了空间的利用率。新哈希表的结构如下所示:
Indices
----------------------------------------------------
None | index | None | None | index | None | index ...
----------------------------------------------------
Entries
--------------------
hash0 key0 value0
---------------------
hash1 key1 value1
---------------------
hash2 key2 value2
---------------------
...
---------------------
你可以看到,它把存储结构分成了 Indices 和 Entries 这两个 array,而’None‘代表这个位置分配了内存但没有元素。
我们同样还用上面这个例子,它在新哈希表中的存储模式,就会变为下面这样:
indices = [None, 1, None, None, 0, None, 2]
entries = [
[1231236123, 'name', 'mike'],
[-230273521, 'dob', '1999-01-01'],
[9371539127, 'gender', 'male']
]
其中,Indices 中元素的值,对应 entries 中相应的索引。比如indices中的1,就对应着entries[1],即’'dob': '1999-01-01'‘。
对比之下,我们会清晰感受到,新哈希表中的空间利用率,相比于旧哈希表有大大的提升。